Testing payload compression in Redis
An idea to limit memory usage of Redis.
Context
Redis is used as a memory store to store the parsing state during processing before serialization in Elasticsearch.
It stores mainly packets, TCP sessions and HTTP communications.
Those resources are quite big, and even with the streaming parsing, they may take up to several GB of RAM.
- Packets are stored for 10s before parsing starts, and removed as soon as their associated communication part (request or response) is parsed completely.
- TcpSessions are stored for 30s after each update, to keep the 'session'.
- HTTP communications are stored only for the sync time with Elasticsearch.
Thus, the biggest data are stored the shortest time.
Idea
In my daily work, we faced OOM issues with Redis, and I suggested to compress the payload stored in it to limit the memory size required...
Guess what? I did not think of it for Spider!
So, let's try what it would give us! 🔍
Requirements
- Compression algorithm is standard and supported by default in Node Zlib. To make things easier.
- It must be fast to sustain the load without incurring too most CPU load increase
- It must effectively save some memory 😉
How to put compressed data in Redis
On first trials, sending a compressed buffer to Redis was not returning the same buffer when reading... 😅
Obviously an issue with string encoding and representation!
I asked GPT4, which informed me that indeed I needed to add the following parameter to either the Redis client (for all methods) or to the method called:
const redis = require('redis');
redis.createClient({
return_buffers: true
});
I wanted first to do a parameter by function, except... that it does not work for Lua scripts calls 😕
I then switched to having two different redis clients if compression is active!
Performance tests context
Load
- Load sample in Flowbird Hub, used for testing:
| Data | Load/s | Compressions/s | Comment |
|---|---|---|---|
| Http communications | 700 | 1 400 | Metadata + Content stored separately |
| Tcp sessions | 800 | 2 400 | 3 steps minimum: creation, parsing start, parsing end |
| Packets | 6 000 | 6 000 | Stored / compressed only once |
- All in all, around 10 000 compressions / s minimum 😲
Before activating compression for good, I needed to validate the effect on the CPU load!
Memory usage
The table below describe an average of content in Redis during the parsing.
| Redis | Content | Size | IO /s |
|---|---|---|---|
| Shared | * 800 HTTP metadata * 750 HTTP contents * 700 HTTP parsing logs | 165 MB | 4 500/s |
| Tcp | * 23 000 Tcp | 310 MB | 19 000/s |
| Pack | * 97 000 Packets | 800 MB | 14 000/s |
We will test the compression effect step by step 😊
Brotli trial
HTTP communications metadata
First, let's try Brotli compression (the most efficient, but slowest). On only HTTP communications metadata.
- Memory usage of Redis went from 165MB to 128MB
- This Redis stores HTTP metadata, HTTP content and HTTP parsing log.
- CPU of parser went from 225% to ... 950% !! 😮
- For only 700 compressions /s !
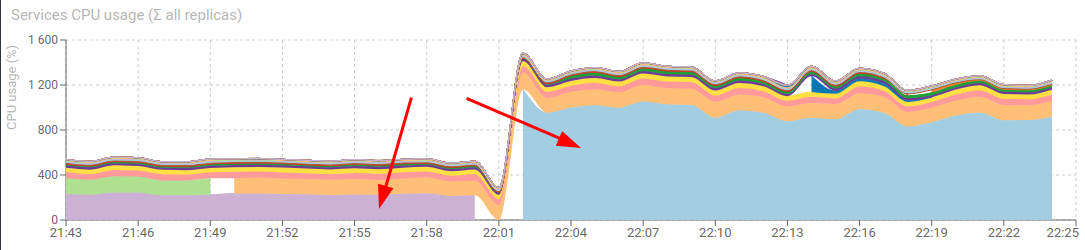
Way too expensive! Let's try with Gzip 😅
Gzip trials
HTTP communications metadata
- Memory usage of Redis went to 120MB ... smaller than Brotli !
- CPU of parser went from 950% back to ... 265% !! 💪
Gzip is definitely better than Brotli for this use case.
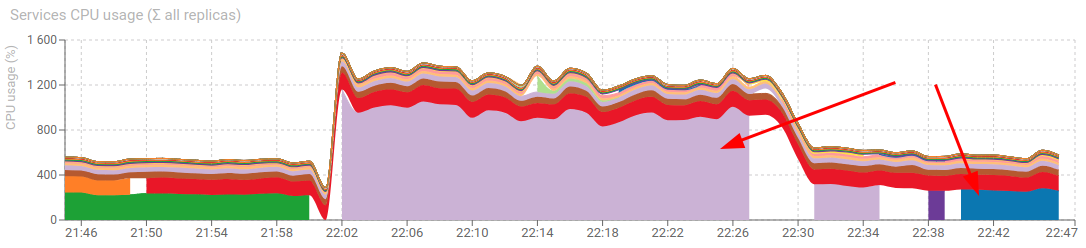
HTTP communications metadata + content
- Memory usage of Redis went from 120MB to 117MB
- CPU of parser went from 265% to 300%
Does not seem worth it.
TCP sessions
| Not compressed | Gzip | |
|---|---|---|
| Tcp-Write | 14% - 92MB | 44% - 96MB |
| Tcp-Update | 30% - 98MB | 76% - 95MB |
| Redis Tcp | 308MB | 119MB |
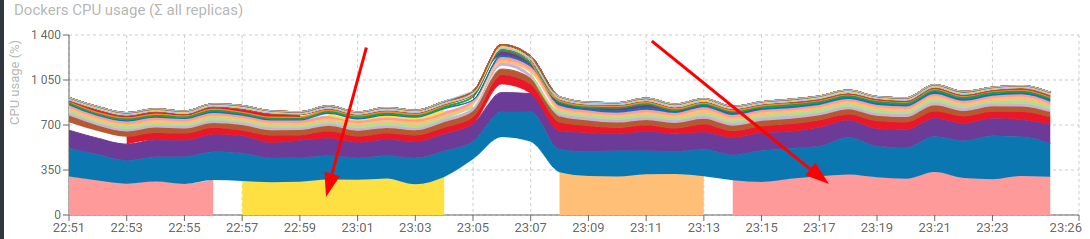
- Memory usage of Redis for TCP went from 310MB to 120MB 💪
- CPU of tcp-write and tcp-update combined went from 44% to 120%! 😕
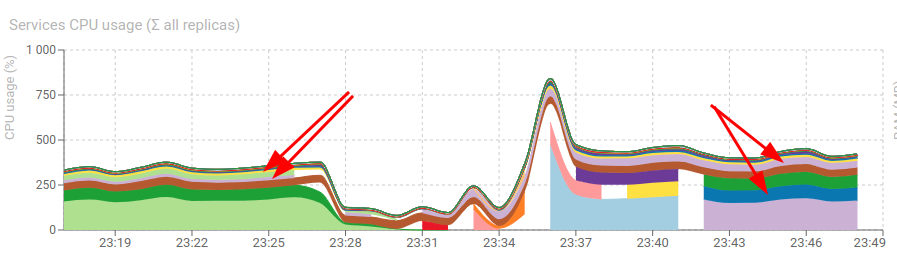
Packets
| Not compressed | Gzip | |
|---|---|---|
| Pack-Write | 42% - 89MB | 154% - 90MB |
| Pack-Read | 62% - 96MB | 88% - 98MB |
| Redis Pack | 419MB | 486MB |
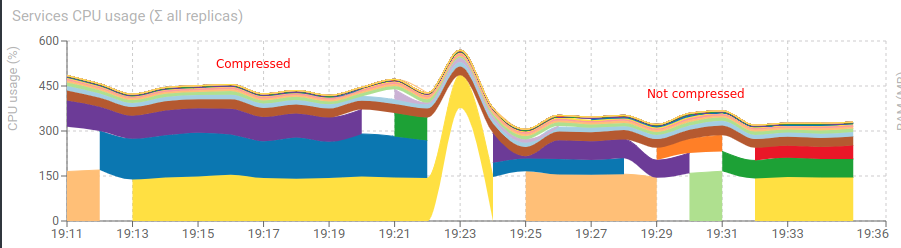
- High increase of CPU usage !
- No memory gain !! 😅
It seems to confirm the little effect of compressing HTTP contents. Compressing base64 encoded payloads (that are mostly compressed) is not useful.
HTTP Parsing log
| Not compressed | Gzip | |
|---|---|---|
| Web-Write | 152% - 108MB | 156% - 108MB |
| Redis Shared | 103MB | 96MB |
- Low increase of CPU usage (2.5%)
- Small memory gain (7%)
Optimising Parsing Status storage
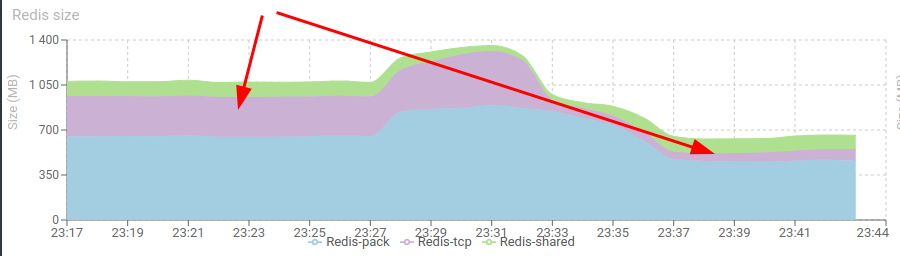
When performing tests, I realised that Redis memory in Tcp and Shared instances was not taken by TCP and HTTP resources, but more by Parsing Status queues, that keep a track on all status for reporting.
I found a clever way to optimise this, and the memory dropped!
I needed then to redo tests of memory improvements, but... this was a nice finding!
Check this out below!
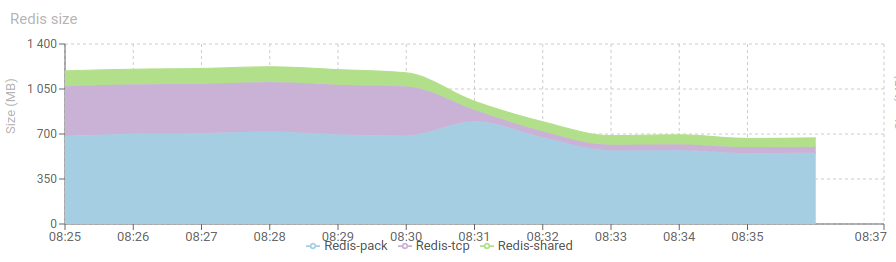
Snappy trials
Well... That's when you realize you damn should read documentation before !
Redis own recommendations:
https://docs.redis.com/latest/ri/memory-optimizations/#data-compression-methods
Redis documentation recommends snappy for compressing before storing! 😅
Let's try !
Packets
| Not compressed | Snappy | |
|---|---|---|
| Pack-Write | 25/s - 72% - 112MB | 45/s - 65% - 113MB |
| Pack-Read | 810/s - 63% - 102MB | 730/s - 73% - 111MB |
| Redis Pack | 87k - 24% - 537MB | 76k - 25% - 551MB |
| Save Packets in Redis | 25/s - 12ms | 25/s - 15ms |
Much better for CPU, but no space savings!
TCP sessions
| Not compressed | Snappy | |
|---|---|---|
| Tcp-Write | 13/s - 17% - 95MB | 13/s - 25% - 116MB |
| Tcp-Update | 67/s - 36% - 99MB | 67/s - 52% - 110MB |
| Redis Tcp | 25k - 10% - 69MB | 25k - 18% - 69MB |
| Save Tcp in Redis | 96/s - 1ms | 95/s - 5ms |
Much, much better in terms of CPU increase.
But no space savings.
HTTP communications metadata + content + parsing log
| Not compressed | Compressed | |
|---|---|---|
| Web-Write | 161% - 124MB | 168% - 122MB |
| HttpComPoller | 9% - 101MB | 10% - 106MB |
| HttpComContentPoller | 8% - 114MB | 9% - 106MB |
| Redis Shared | 104MB | 85MB |
Low CPU increase, some space savings.
Side idea
As we can see that compressing at high frequency has an important CPU cost, I wondered if... avoiding compressing JSONs before sending over HTTP would reduce much CPU.
Modified services calls
I then implemented flips to avoid compressing communications between:
- WebWrite ⇄ PackRead - GET /packets/of/tcpsession
- 700 calls/s
- response with n packets
- WebWrite ⇄ TcpUpdate - POST /parsing-jobs
- 37 calls/s
- response with ≤ 20 sessions
- WebWrite ⇄ TcpUpdate - PATCH /tcp-sessions
- 37 calls/s
- request with ≤ 20 sessions
Results
To compare with and without compression, I compare the total CPU usage of services Web-Write + Tcp-Update + Pack-Read:
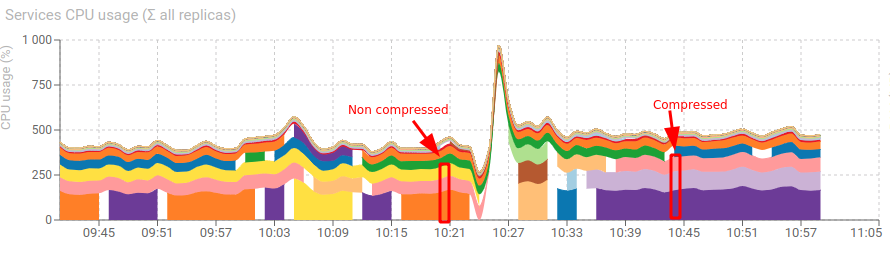
Average over a few hours:
| With compression | Without compression | |
|---|---|---|
| Web-Write | 180% - 107MB | 170% - 105MB |
| Tcp-Update | 36% - 99MB | 78% - 87MB |
| Pack-Read | 111% - 94MB | 71% - 95MB |
| GET /packets/of/tcpsession | 32ms | 25ms |
| POST /parsing-jobs | 22ms | 20ms |
| PATCH /tcp-sessions | 24ms | 23ms |
...
PackRead is better without compression, when TcpUpdate seems better with!
Let's then try the mix:
- without
GET /packets/of/tcpsessioncompression - with
PATCH /tcp-sessions+POST /parsing-jobscompression.
| Tcp-Update compression Pack-Update non compression | |
|---|---|
| CPU Web-Write | 149% - 111MB |
| CPU Tcp-Update | 34% - 100MB |
| CPU Pack-Read | 61% - 100MB |
| GET /packets/of/tcpsession | 800/s - 22ms |
| POST /parsing-jobs | 42/s - 15ms |
| PATCH /tcp-sessions | 42/s - 15ms |
Conclusion
| Compression | Interesting |
|---|---|
| Packets in Redis | ❌ |
| Tcp in Redis | ❌ |
| HttpComs in Redis | ✅ |
| HttpComContents in Redis | ✅ |
| Http Parsing Logs in Redis | ✅ |
GET /packets/of/tcpsession | ❌ |
POST /parsing-jobs | ✅ |
PATCH /tcp-sessions | ✅ |
Even if due to high streaming throughput, the memory usage is not big, on spike it can grow much.
Compressing it will give us more breath, especially for HTTP communications resources.
However compressing and already compressed Base64 payload... does not bring anything 😅
As a bonus I found a way to limit memory usage for Parsing Statuses. 😁
Cheers,
Thibaut