Shutdown delay
· 3 min read
I introduced a shutdown delay on all microservices to postpone their shutdown.
Kubernetes control plane need this time to update the Load Balancer to tell it that the services get unreachable.
I introduced a shutdown delay on all microservices to postpone their shutdown.
Kubernetes control plane need this time to update the Load Balancer to tell it that the services get unreachable.
Upon Ophelien request, you may now filter columns in columns selection popin:
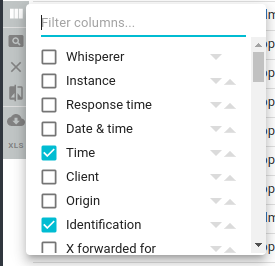
With Spider scaling with many teams and whisperers, it became easy to get lost on what team or whisperer was currently selected.
Trainings have revealed that something was missing!
I had the idea to integrate 'selected' badges left to filter badges!
You now have access to tags filter in the menu. No need to add them on the grid anymore to filter on tags.
Filtering headers is now done once parsing is finished, thus allowing to:
And then, remove unwanted headers, such as... authorization passwords ;-)
So, you still know who called, but you're not disclosing its own password.
Neat, isn't it?!
Spider has recently been setup to observe Mobile Payment Platform of Flowbird.
It brought its set of surprises and 'not managed' cases, leading to improvements in parsing :)
But new users really like it!!!
On Kubernetes first month, Spider had two downtimes because the polling queues got filled with tens of thousands of items, and no alert got raised.
Since Spider moved to the Kube, I needed to fix some of the monitoring dashboards to work on Kubernetes.
Here are the changes:
The first training brought many improvements ideas.
A few of them have been implemented straight:
Kubernetes brings autoscaling, and it's magic!