Today, checking monitoring at the end of day, I found a spike of 'parsing errors' in the morning. The monitoring helped me find out why. take the path with me:
1 - Looking at the logs dashboard 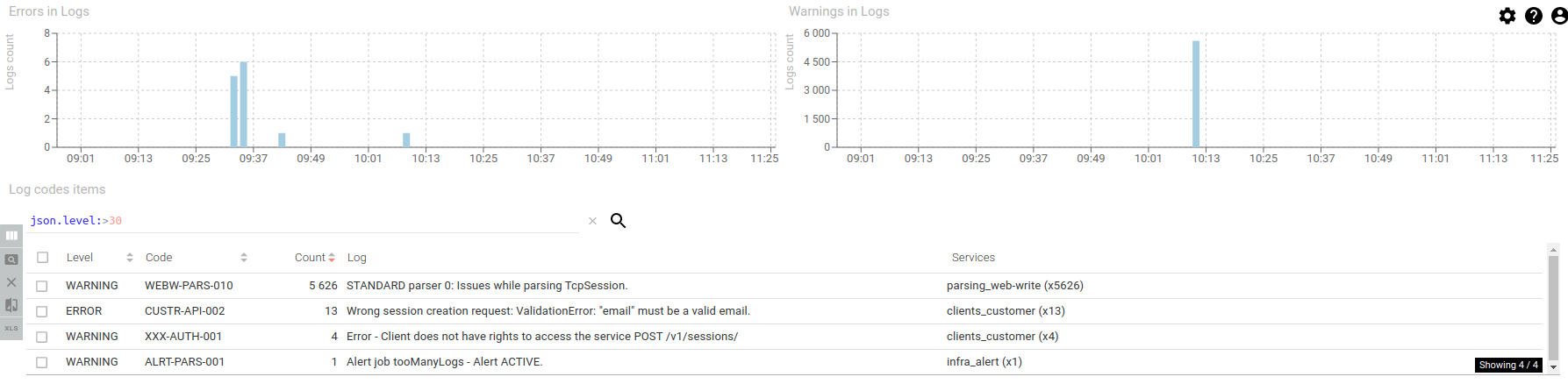
We can see a spike in logs - nearly 6000!! - around 10:13. The aggregation by codes show us very easily that there have been parsing issues, and when opening the log detail, because there were missing packets.
Let's find the root cause.
2- Looking at the parsing dashboard
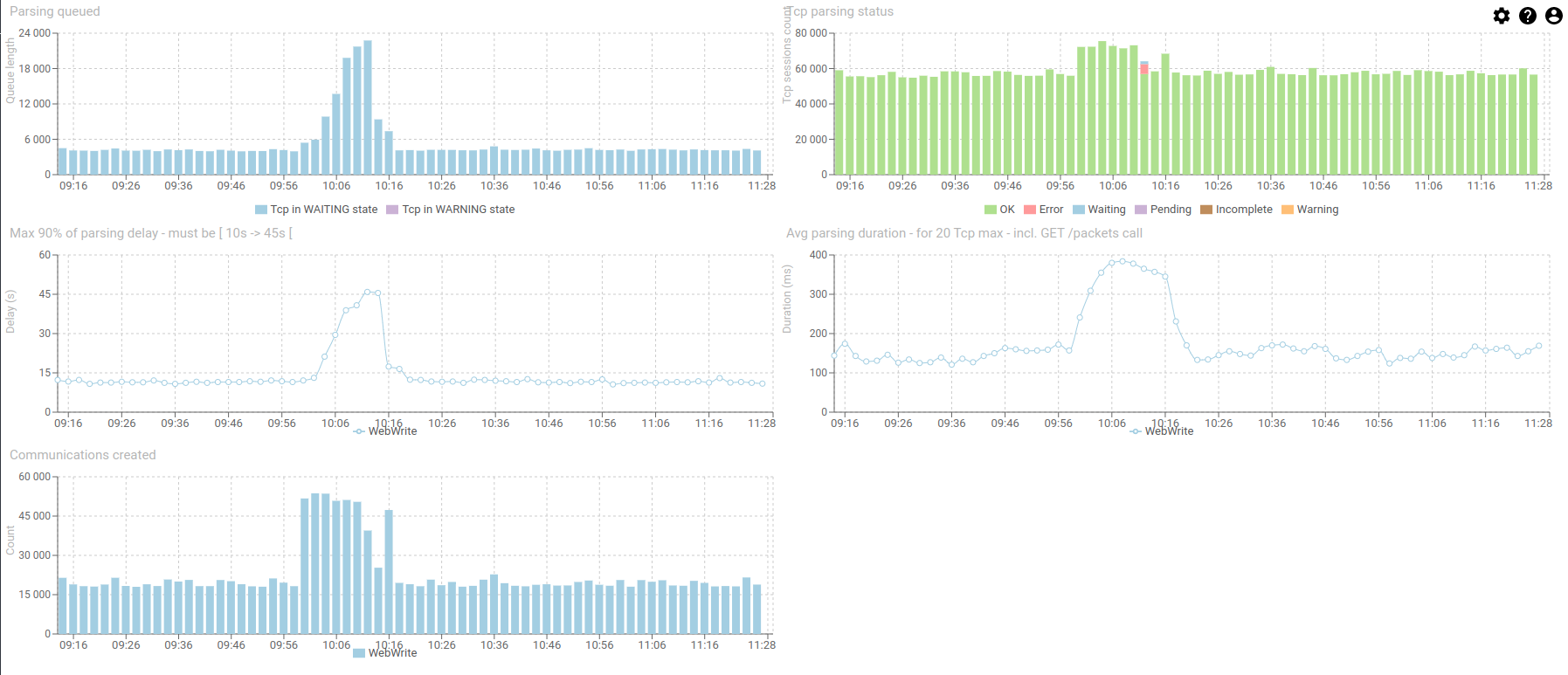
We can see an increase of Tcp session in waiting to be parsed in the queue, and the parsing duration and delay increasing.
Many HTTP coms were still created, so there is no like, errors, but only in increase of demand.
There is a small red part of the Parsing status histogram, with 5603 sessions in errors out of 56000.
3- Further on, in the services dashboard
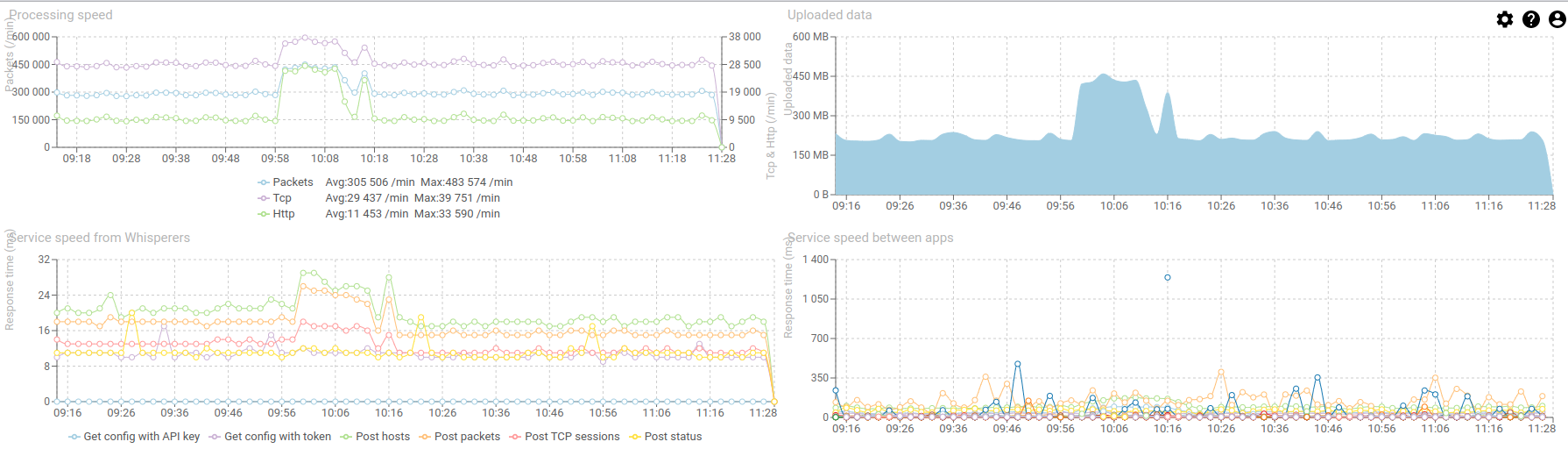
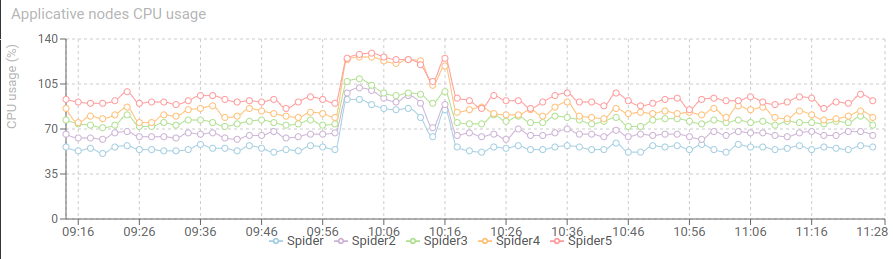
There is definitely an increase of input load, and an even more increase of created Http Coms. The input load almost doubled in size!
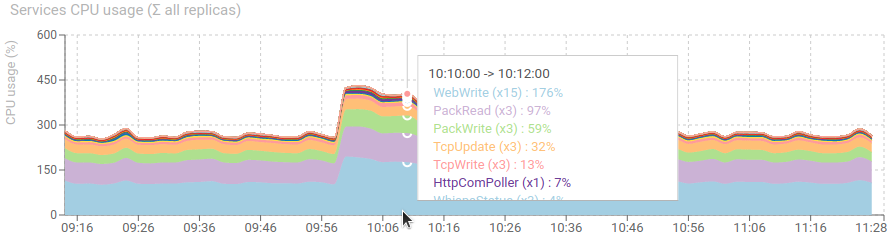
CPU is still good, with a net increase of parsing service.
4- Looking at DB status

Redis doubled its load, with a high increase in RAM, but it came back to normal straight after :) Works like a charm!
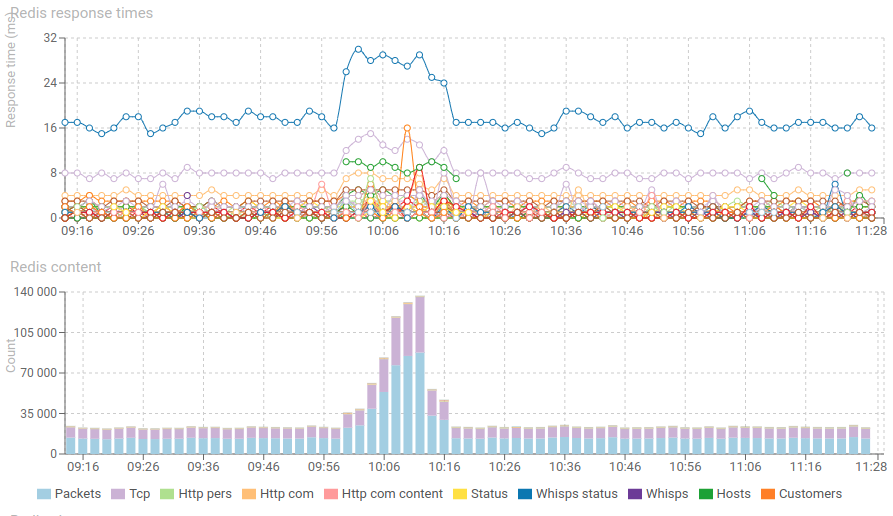
Response time and content of Redis increase significantly but nothing worrying. The spike has been absorbed.
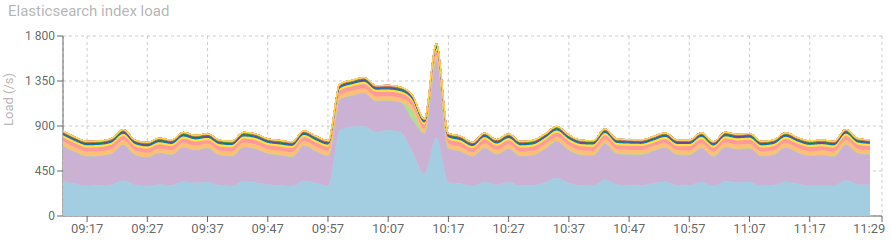
Elasticsearch shows a net increase of new communications indexation.
5- Then the whisperers dashboard gives us the answer
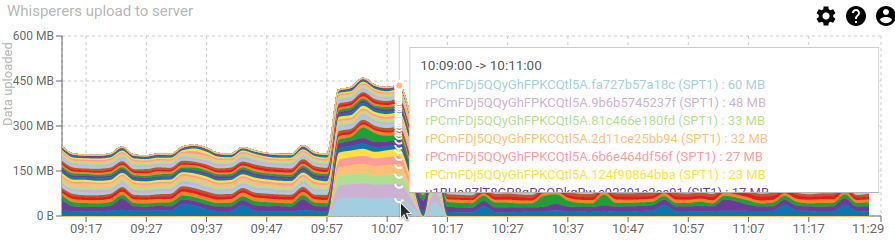 In fact, all was normal, it's only the performance team (SPT1 whisperer) that decided to capture one of their test :-)
In fact, all was normal, it's only the performance team (SPT1 whisperer) that decided to capture one of their test :-)
That's good observability capabilities, don't you think? All in all, everything when well.
- The spike was absorbed for almost 15 minutes,
- But the parsing replicas where not enough to cope with the input load, and the delay of parsing increased regularly
- So much that Redis started removing data before it got parsed (when the parsing delay reached 45s, the TTL of packets)
- Watch again the second set of diagrams to check this.
- Then the parsers started complaining about missing packets when parsing the Tcp sessions. The system was in 'security' mode, avoiding to crash and avoiding the load increase.
- All went back to normal after SPT1 stopped testing.
The system works well :) Yeah! Thank you for the improvised test, performance team !
We may also deduced from this event that parsing service replicas may be increased safely to absorb the spike. As the CPU usage still offered room for it. Auto scaling would be the best in this case.
Cheers, Thibaut
























