They allow you to build constant aggregate of some of your index and save it for later search. Searching on rollups can be combined with searching on original index at the same time. This offer great flexibility, ... but come at a cost.
Rollup searches are slow :(
Context
I already removed two rollups from Spider because they were I needed more flexibility on the way they were built: I needed the ability to update a previously rolled up result. Which is not a feature of rollups.
So, I implementing live aggregation of two data: Tcp Parsing Status, and HTTP parsing status. Both status are preaggregated at one minute interval and stored in the own rotating index. It required extra development, extra pollers, and new indices, but it works great, with gret speed.
At that time, I decided to let the last rollup be, because it was aggregating Whisperer capture status information, which cannot be updated.
However, I noticed with monitoring that searches on this rollup where slow: around 300ms! For an index of a few megabytes !! Really not was is expected from Elasticsearch
This Rollup search was used to gather part of the timeline quality line information, as was generating some timeouts in the worst cases.
Rework
I decided to do as for the previous rollups:
- New script in Redis when saving whisperers' status, that aggregates the capture status on a minute based interval
- New poller configuration to poll the minute based aggregated data and store it in Elasticsearch
- New index to store the aggregated resource, with its own ILM and rotated indices
- And all of this is integrated before release in the monitoring. Which helps a lot!
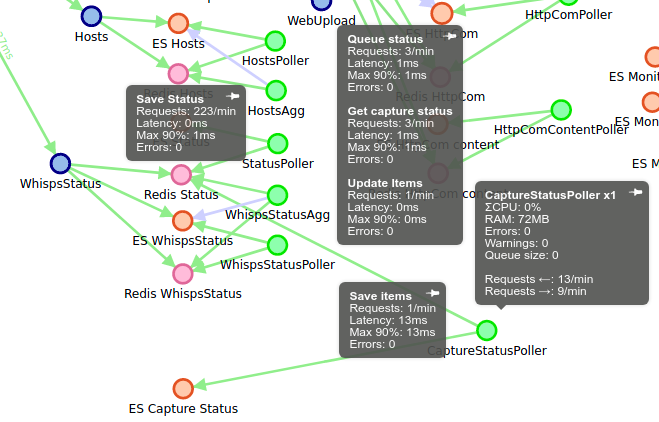
All this was deployed seamlessly with the automated Setup :-) And the result is up to expectancies !!
- Removal of rollup job searches on the index every second (still good to take)
- Optimised process with Redis
- And much faster searches: 70ms in average, more than 75% over a week of measurements.
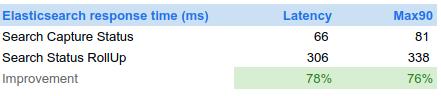
Conclusion
Elasticsearch Rollups are great to test that preaggregating data speeds up queries, and to work on how to aggregate them. But current implementation of Rollup search is slow, and you'd better:
- Either use search on the Rollup index (and not rollup search)
- But then you cannot benefit from searching both rolled up index and source index
- Either implement your own aggregation process, and optimise it on your use case. Which I did.
Cheers Thibaut










