Many things have evolved since last time I wrote here.
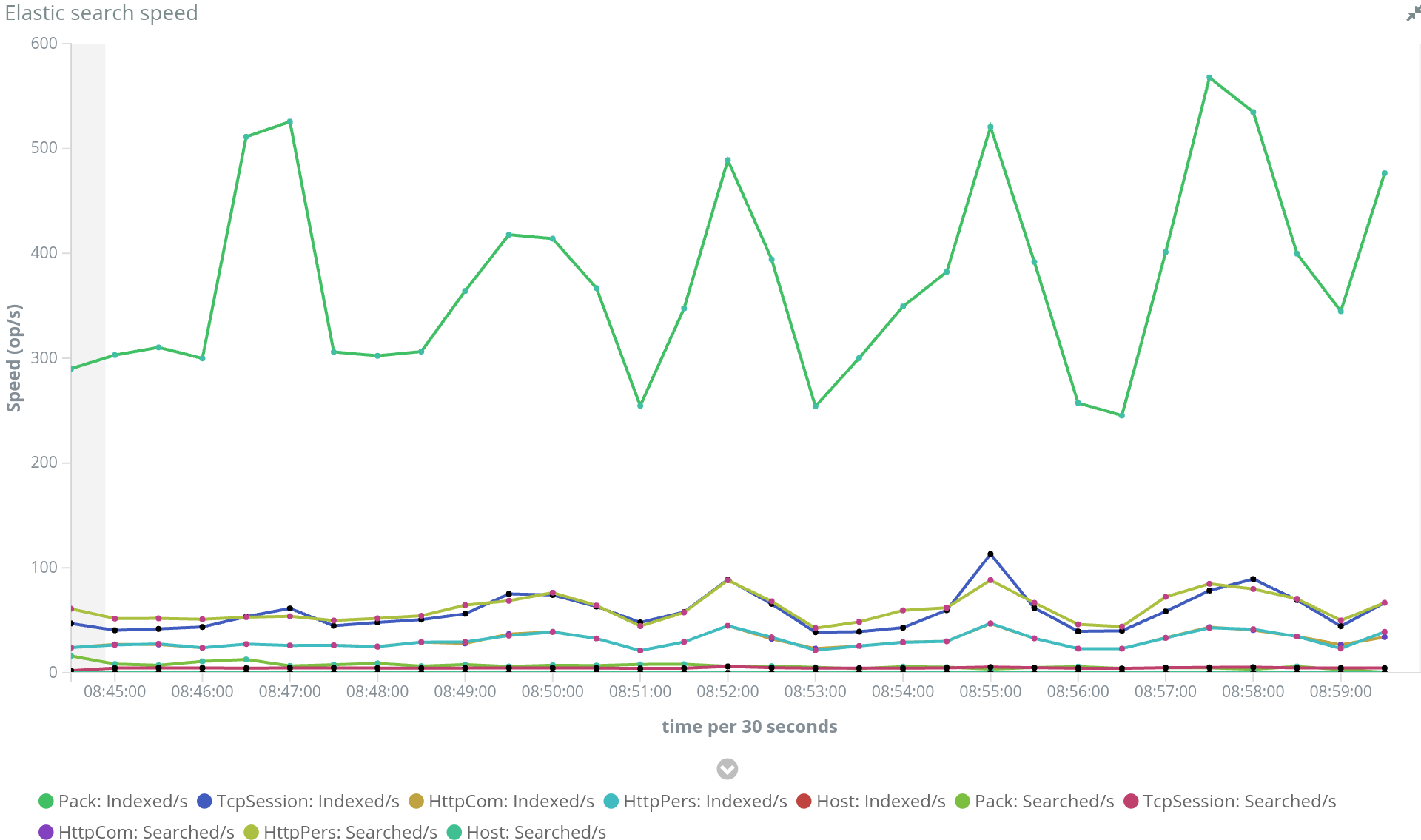
Spider went from monitoring 5 000 packets by minutes to 45 000 packets by minute, with more than one month system stability. And it was some challenge. Indeed, one goal was to limit at maximum the size of the needed servers.
The architecture changes I put in place are as follows:
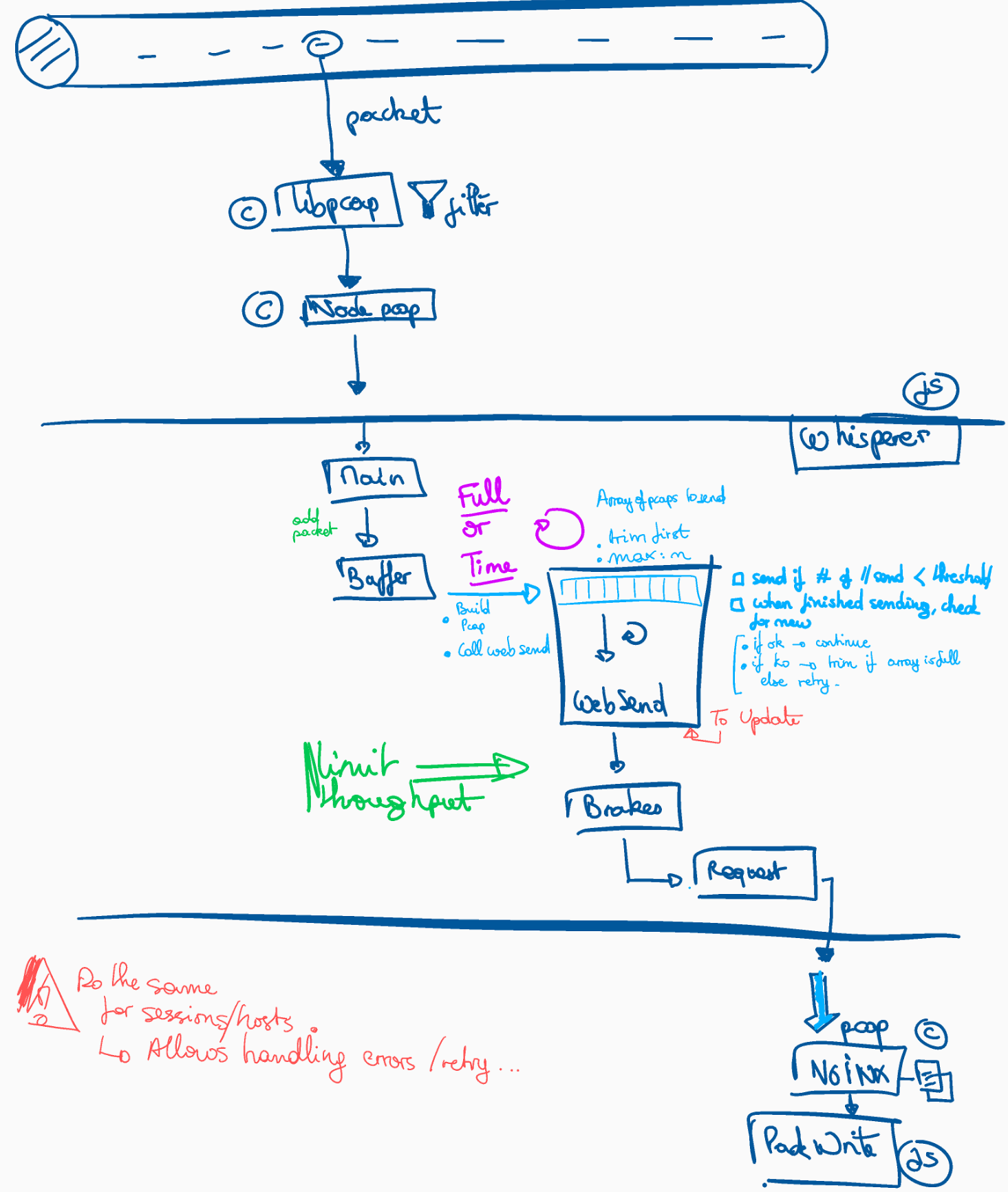 First, Whisperers were sending packets on the fly in asynchronous mode, without carrying much on results (except for circuit breaker).
First, Whisperers were sending packets on the fly in asynchronous mode, without carrying much on results (except for circuit breaker).
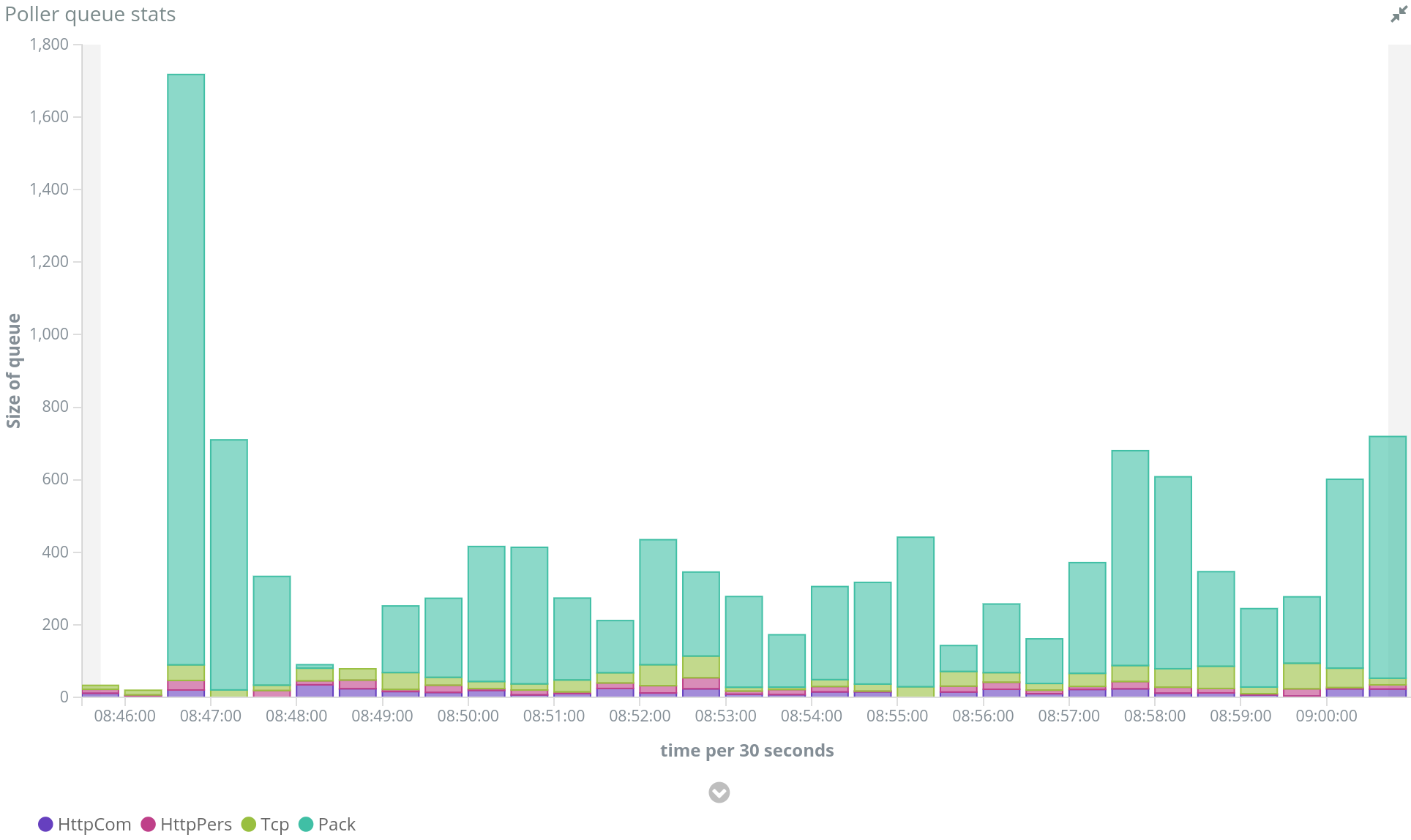
Now, they have a limited number of simultaneous connections to back office, with a queue for stocking packets to send later. This is similar to a connection pool for DB. When packets overflow the pool, this is tracked in the monitoring.
This allows smoothing spikes of network traffic on the client side to reduce the impact on the server.
Retry pattern is bad in real time systems.
I had several retry implemented throughout the system to handle occasional 503 or time outs. And to handle synchronisation delay between packets and sessions.
The issue is that when something get bad, referring helps getting the process done, but new comers get stacked up. And the issues accumulate. Especially if getting don't solve the previous one and you have been delaying processing for many seconds.
I removed retrials done during processing to keep only those for configuration and synchronisation (polling).
Errors on processing are marked and reprocessed once by another process ten minutes after. Then I can get errors on the fly, most of them being solved later. If not, then, they are definitely errors.
Node is mono threaded. For it to answer to connection requests, you have to give the have back to the event loop as soon as you can.
I added setImmediate calls in the processing loops, this got rid of most of my 503s.
Redis is a great in memory database. It gives building blocks for many many architecture patterns.
However, things that looks easy out of the box need to be taken with care. There is no magic.
Redis has a feature of automatic removal of volatile keys. However, to find keys to remove, Redis pick 20 keys at random every 100 ms, and if more than 25% keys were to be removed, it loops!
As I am using Redis as a write ahead cache, I use volatile keys to clean the DB automatically. But at the end, this kills Redis performance, and I had timeouts while calling Redis! Keys should be removed explicitely whenever possible.
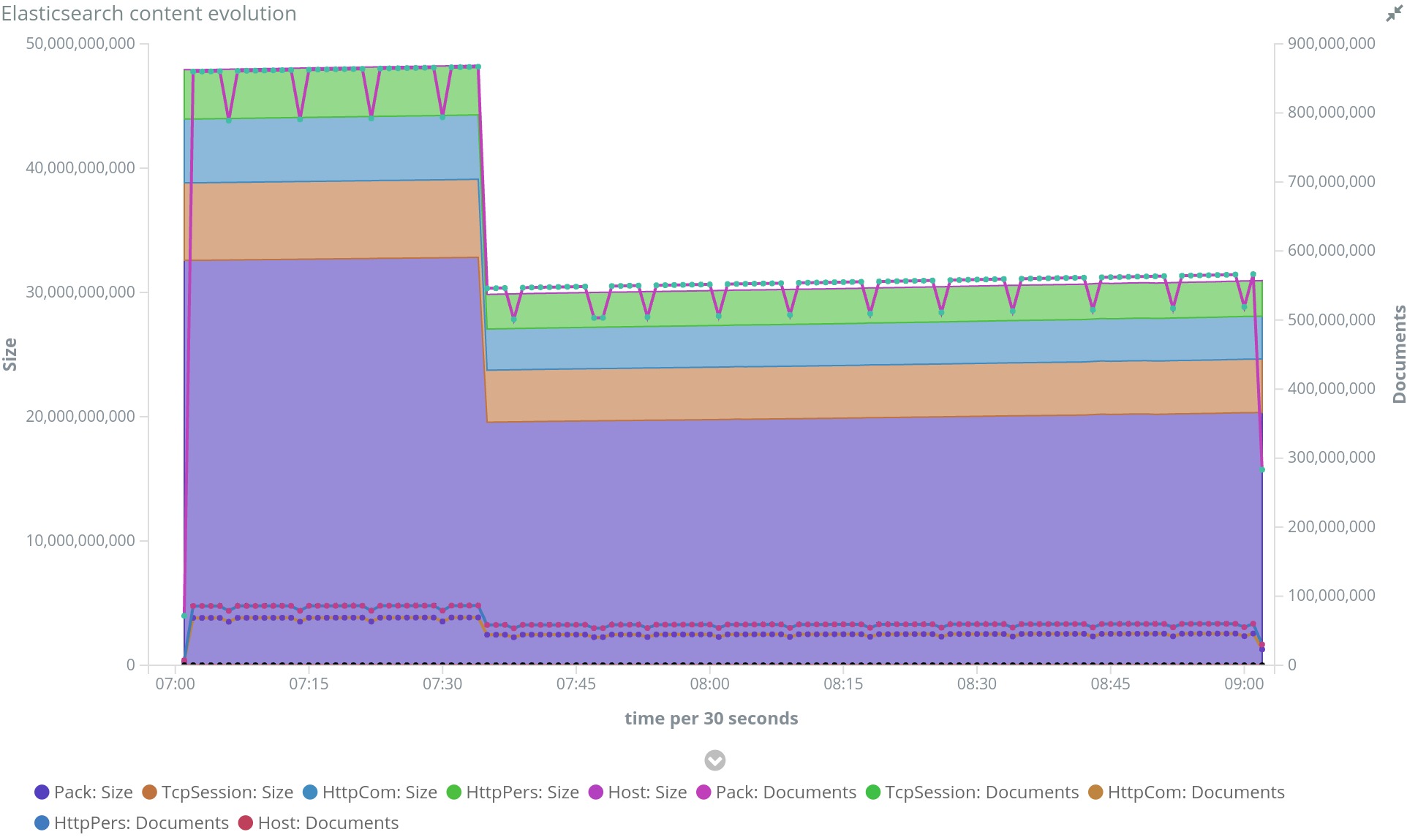
I made many changes in the data flows to remove processed data from Redis as spoons as the data was synchronized in ES and not needed any more for real time processing. This brings a lot of complexity in the data flow, but this is pretty much handled at 75% by setting lifecycle to resources and checking it in the pollers. Only exception is packets that are asked to be removed from Redis by the parsers.
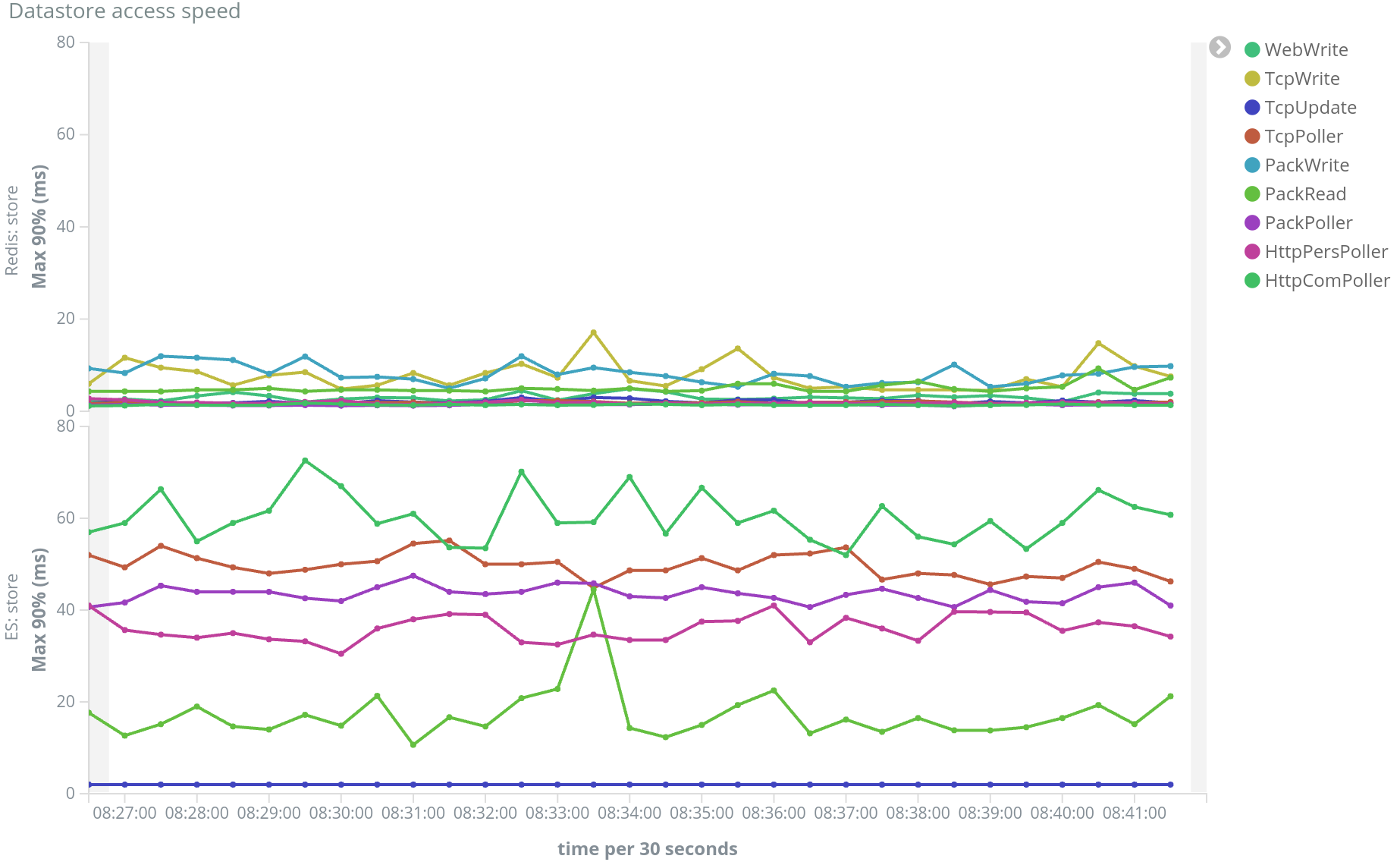
All this made Spider go from 50 000 items stored in Redis in continuous flow to... 400 ;-) And from timeouts to Redis, I achieve now 20 ms in max 99% !!
RTFM they say =)
I also moved Redis outside the Swarm. Indeed, I found issues in stability of Redis in Alpine containers.
Manual removal of items from Redis implied pipelining lots of instructions and complex preparation on client side.
Redis documentation advises against it, and favor going to Lua server side scripting now. Lua is integrated in Redis and allow scripting Redis calls, while manipulating and checking Redis responses while still on the server. It also allows parsing and modifying JSON objects and can return values, arrays or hashes to the client.
The scripts do not need to be send to Redis for each request and are cached on the server. The client can call a script execution using the SHA signature of the script. Simply enough, my microservices subscribe the scripts to Redis at start, or on Redis reconnection.
My main difficulty was to understand enough of Lua to do the scripts I needed knowing there is no example of 'complex' scripts available in the web resources. And there is no debugging embedded in current Redis version (but it is coming!).
The performance improvement is huge, and this simplifies much the client processing. But it must be keep in mind that, as the processing is done on Redis server side, it is less scalable than when performed in the application layer.
When you index in Elasticsearch, you may provide the id of the document, or let ES generate it.
Choosing a good id as much performance impact on the indexing process.
Providing the id on the applications layer is easier for direct access and updates. However, this makes ES search for a document with existing id whenever you index. In order to update it, or not.
This slows down indexing.
If you don't provide the id, ES generates on the fly a global unique id for each document, and don't check previous existence. Much faster.
I moved packet indexation to automatic ids, since I never update them.
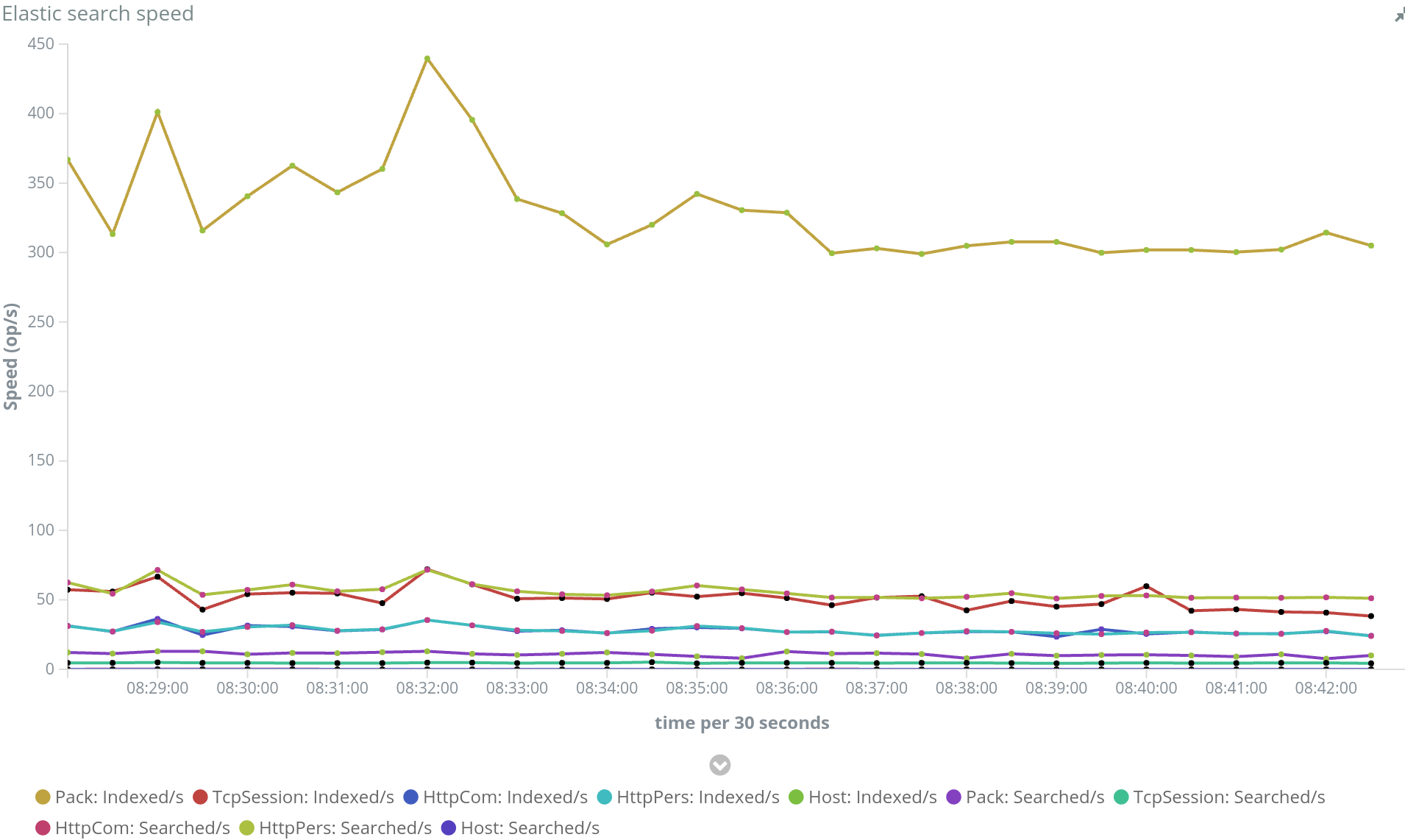
Another quick indexing performance improvement on ES concerns refresh rate (I am already doing bulk requests all over the place). Default refresh rate is at 1s. It is the time that ES waits before closing current working segment and making it available for searching.
As ES is used for display and not any more for real time processing, I slowed down the refresh rate to 5s for packets, and 2 or 3s for web and tcp indices.
ES is multithreaded. Rather than sending big chunks in serial, it is best to send big chunks in parallel. ES has as many indexing threads as there are cores on the servers. And when sharding is in place, it can index on all servers.
The best setting is to be found in size of index pages, number of application indexing threads and so on...
When the loading increased in Spider, I met a moment when the new packets were piling up faster than they were consumed... one command in Docker Swarm to scale the pollers, and it as settled. I love this :-)
NGINX default settings are not for system under load. They need change to be able to handle hundreds or thousands of requests by seconds to upstream servers. This own NGINX documentation is the base for first tuning actions.
Main changes applied:
- Use HTTP 1.1 between NGINX and upstreams to keep connections open.
- Increase timeouts for connection to upstreams (needed to be compatible with Node monothreaded architecture): proxy_*_timeout
When the load increase, concurrency issues show up! ;-)
- I implemented concurrency checks in Redis thanks to Lua.
- ES offers a great system of version control to implement custom concurrency checks. That helped me get out of it !
Microservices are great for development and maintenance. However I'm often impacting many services at once when developing new features. You need good team communication to be able to work it out. No issue in my case :)
When scaling, scaling independently is definitely great. But sometimes, finding the good tuning when you need to increase scale of several dependent microservices is difficult. Polling instead of pushing is a good solution, but sometimes you need to scale B for more processing load, but B depends on A to get its data. So you need to scale A as well.
If A is doing processing (and not only offering data) this can prove a challenge.
I had the issue in Spider:
- Web parsing microservices was calling Packet read service
- The reassembling of TCP packets was made in Packet read
So, both microservices were doing heavy processing, and scaling them was difficult tuning job.
I moved the reassembling of packet knowledge to a library and included in the Web parsing microservice. This relocating the scaling need as the load was only performed on parsing module, and the Packet read was focused only on getting and formatting packets.
This simplified the configuration of the cluster. For a single heavy loaded business process, it is easier if the high CPU processing need is focused in one place.