Troubleshooting no response as scale
When finding issues on Flowbird production deployment of Spider, we noticed that there were a small pourcentage of communications that had no answers.
There were not esily noticeable as very small number. But this was abnormal since the application seemed to live good without them.
It could be a bug in Spider!
And it was... or only part of!
Bug seems to be in Redis!
Here is the story of the troubleshooting.
Saving Tcp and Packets to check bug location
First I changed parsing configuration to save both Packets and Tcp sessions to Elasticsearch to have access to all raw data and understand the situation.
It showed me that indeed, all packets were captured and that there was no factual reason for the communications to be saved with only the requests and no response!
There was obviously an issue in the parsing process. 😰
Architecture being troubleshooted + seq diag
Architecture diagram
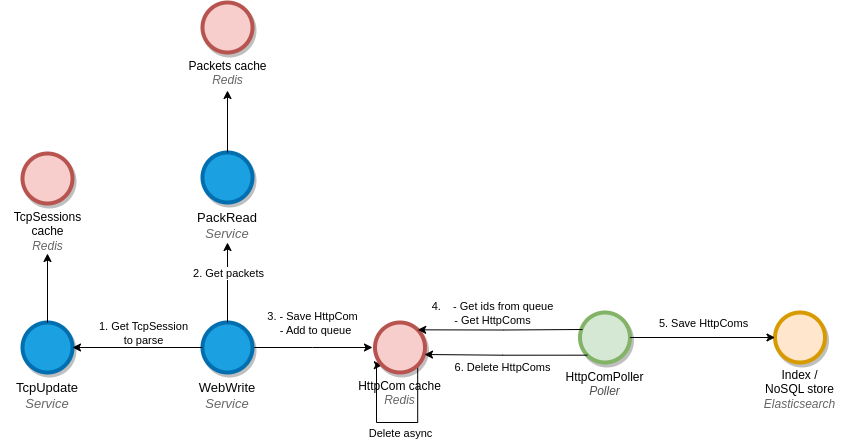
Process
- WebWrite receive a TCP session to parse
- WebWrite asks for Packets to rebuild the communication
- WebWrite saves to Redis the communication to save to ES, using a Lua script
- To a sorted set acting as a queue
- As a string value, index by the communication id
- Poller reads the queue
- Poller saves to Elasticsearch
- Poller removes from Redis or requeue on error
Load figures
For the system under test:
- 520 communications /s average
- 6000 operations /s on the Redis saving communications
Code review
The issue with that scale is that reproducing the unitary issue is a challenge.
I knew, for sure, that at low speed the issue does not present itself.
I have 100% reliability and consistency at low scale.
So first, I reviewed the WebWrite code to understand how a race condition could happen and that process would not store the response.
I turned it upside down in my head, decomposed it, modeled it. But bo, nothing seemed wrong.
For me, I was saving all versions of the communication without any race condition not managed. 🤨
Adding specific logs to manage the scale
In despair, I decided to add logs to debug.
But I could not plainly activate debug mode which would mean millions of logs every minute at this scale. 😨
So I created specific versions of Poller and WebWrite services that I supplemented in the cluster thanks to the override
options in the Helmchart. 💪
I introduced 7 specific logs... Which resulted in tens of thousands of logs being thrown to the cluster every minute.
And the cluster couldn't cope with it! 😆
I'm using Filebeat and Elasticsearch to capture logs. And not all logs were getting to Elasticsearch.
In fact, Filebeat has a throughput threshold and trashes events above rate threshold! 🤔
Scaling pollers to reduce log throughput per node
Instead of increasing that threshold, I scaled the Pollers and WebWrite replicas to reduce the number of logs per node, and thus, per Filebeat instance.
Then oh surprise!
For nearly all communications that where missing a response, I could find in the logs both versions of the communications were rightfully parsed and saved to Redis by WeWrite! With their correct associated version (to manage concurrency).
So... I was right in my code analysis: the streaming parsing process is good! 💪
And on the poller side, all communications fetched was correctly saved to Elasticsearch! Where the heck was the issue then? 🤔
More logs on pollers
In the poller code, I had a safebelt removing any empty communication found in Redis...
By empty, I mean:
- The id is in the queue
- The communication content matching the id is not found in Redis
Except this safebelt was silent: no log was emitted if any empty communication was found!
Then, I missed observability! 😡
So I added logs there... And, magic! This log got emitted every time I had an empty response. 💪
That's a good log to keep for later!
Understanding the issue
That meant that the communication are removed in Redis:
- After WebWrite saves it and queues it
- Before the Poller fetches it
But the only one removing the coms from Redis... are the poller after processing... Damn it, yes, after processing!
First race condition found in Spider
So there is indeed a race condition:
- The poller is saving ids in ES
- WebWrite is saving the new version of the same ids
- The poller deletes those ids from ES (the new version!)
- The poller unqueues the new versions... but cannot find the ids!
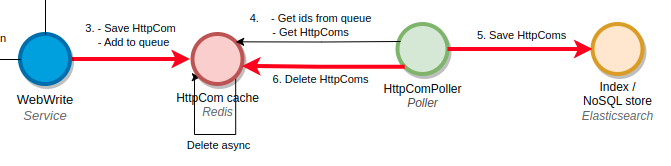
I then changed my code to remove the ids from Redis as soon as I was dequeuing them. And I managed errors differently by, instead of only requeuing:
- Requeuing
- AND saving back items to Redis, only if the item is not present (SET EX command)
Let's check the impact:

... Well...
Good and not enough!
Indeed, a very small continuous count, of empty responses has been removed.
But what did I miss? There are still many, and... as spikes?
Second race condition found in Redis - bug?
It troubled me much of the day, working with ChatGPT and looking at Redis documentation...
Finally, I found something:
- I was using Redis
UNLINKcommand that does asynchronous deletion of the items - So maybe:
- Redis is registering the delete commands of the items
- Then WebWrite is saving a new version
- And Redis is effectively removing them
- Except that Redis removes the new version, not the one I asked for deletion!

I then changed my code to use Redis DEL command.
And here is the result:

Nicer!
Looks like I was right, UNLINK has some flaws. But changing to DEL does not fix all cases ?!
There must be something else, still!
Change of approach - applicative delay for removal
I then changed approach after some thinking:
- Let's remove the communication from Redis ONLY after it cannot be updated anymore.
- That means having more data in Redis, but it could solve the situation (and confirm a bug in Redis?)

It looks better, but I'm still using UNLINK... And we still have some cases.
Some are correct (we indeed did not receive the answer), some are doubtful.
And the impact in Redis memory is clearly visible:
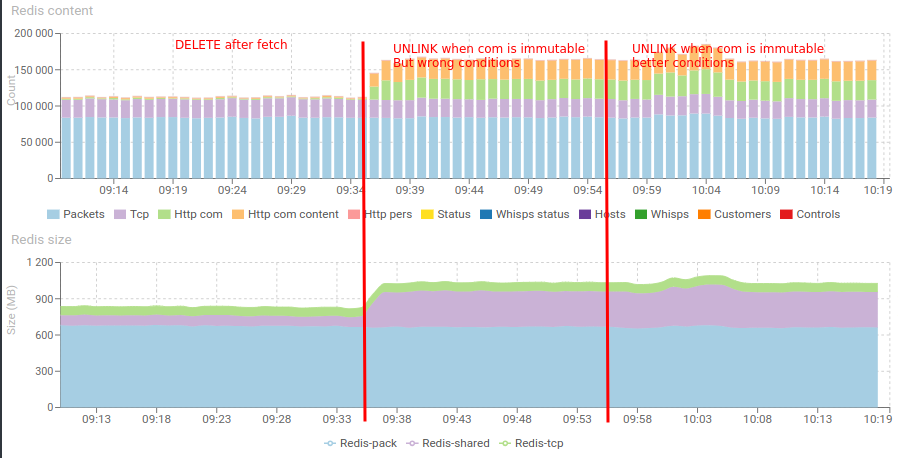
Solution is better but not perfect, and it implies a degraded mode in Redis management with more communications kept longer.
Which implies an increase of 200MB to only keep communications a few seconds more in memory.
This would ultimately prevent scaling.
I'd rather find another way to make deletes work straight after fetching the data.
Change of approach - no more updating in Redis
I then had another idea, changing approach one more time:
- Let's not save the same communication id twice in Redis, but only in Elasticsearch
- By adding the version in Redis key identifier, we can
UNLINKthe keys as soon as there are fetched without impact of the other version storage. - And focus about having a unique id for both only on Elasticsearch.
And here is the result:

Looks similar to DEL solution or to applicative delay solutions.
So, all these solutions were good.
The latter being to most sure. Let's keep it.
It seems like there is another issue that, sometimes, generates a series of missing data in Redis while the link is pushed in the polling queue...
...
Next day, I add no log of Missing data when fetching from Redis during 9 hours and 13.4 Million communications parsed.
Then the load increased during the day and I add again the issue!
There were still some communications missings responses when they should not! 😳
Why again? What did I miss? 🤔
Yet another race conditions on Polling queue
After some long thoughts, I found that the issue could be due to:
- The fact that polling queue is sorted on
_updatefield- It contains the sequence number of the packet that generated this communication in the TCP session.
- Before a previous refactor, it was based on updateDate! Which was safer! 😳
- Then some httpComs could stay too long in the queue before being polled
- Then those would be removed automatically by Redis thanks to the
TTLsetting (set to 45s)
This was quite possible.
And logs confirmed it:
- Log at
2023-11-27 17:39:34.399 - For a missing response of a communication parsed at
2023-11-27 17:38:50.007 - We were indeed in the 45s range!
It a slowness race condition 😆
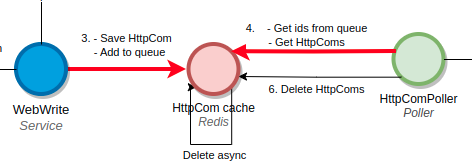
I then changed the queue to a list of ids, as the zset was not anymore needed.
And... Miracle! No more strange missings!! 💪💪
I finally solved it ! 🍾
Summary
Long work but the progress is visible :)

End result:

167 communications missing responses in 10 hours!
I checked some... It's indeed due to the application under observation 🤗
3 race conditions found!
Like the tree hiding the forest story!
Exhausting, but it was worth it! Spider parsing has never reached that quality and I'm sure it beats anything on the market 😁💪
I'll give it a few days to check, then I'll release the changes.
Word of notice
Sometimes, there is a spike of communications with 'no answer', but if you open their details, you will see their answers...
The reason is that the first saving of these communications was done just before the index rotated!
And the final versions, a few seconds later, are saved on a different index.
Thus Elasticsearch returns the 2 documents.
Spider manages it, and returns only last version, when getting single communications, or when searches returns both.
Bot not if your searches return only the first version. Or when doing aggregations - like for the timeline, or on the dashboard.
Any comments?
Cheers,
Thibaut