When shards routing gets a bottleneck
Depending on your architecture, Spider defaults settings may not be right.
When you are having big ingestion load with only few Whisperers... you may have a scaling issue!
Let's see how to overcome it!
Context
In Streetsmart, when recently moved to Kubernetes.
With this move, we reduced the amount of environment, but not the global load. On the contrary, with more and more automated tests flowing in.
The result is that Spider got less and less Whisperers connected to it, but their packets / ingestion load kept increasing.
Up to a point when... Elasticsearch could not absorb the ingestion load!!
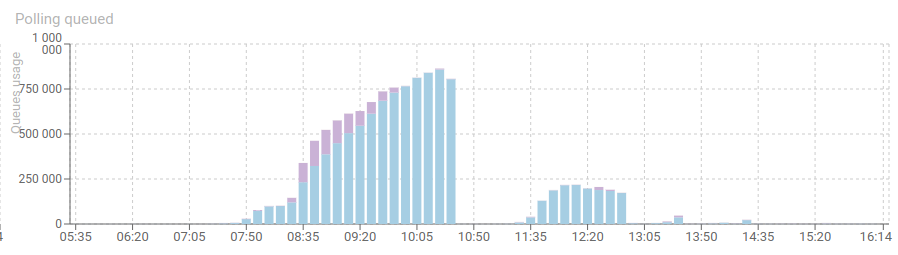
We did scale it vertically, but there is a decent limit to it.
Indeed, by default, Spider is routing all the data of the same Whisperer to the same shard. Using the routing features of Elasticsearch indexing and searching.
- This makes searches faster, as Elastic does not have to query all shards to find the data, but it can access directly the right one.
- However, this limits the scaling as all indexing for the same Whisperer is going to a single node / shard.
Issue
In Streetsmart case, we had 3 nodes, but 2 main Whisperers. And ES was having difficulty indexing all the input (5000/s) with the 2-4 cores associated.
We scaled vertically, and it worked.
Except that one node was also scaled, while doing nothing: the data of the whisperers where indexed on only 2 of the 3 primary shards!
Scaling horizontally was having no effect... when it should be the most efficient.
So I've got the idea to move this routing to an option, a tuning option.
And I added it to the setup.
See: https://spider-analyzer.io/docs/operating/tuning/tuneHighLoad#shard-routing-option
Improvement
- I added the option to the common part of the services configuration, and valued it from the setup scripts.
- I modified all (11) services doing indexing, search or delete of these routed data to:
- Route by
whisperervalue when the flag is active - Do not specifically route otherwise
- Route by
So doing, when set to false (the new default), the routing is random.
Which results in the indexing load being more evenly distributed across the shards!
Result
The graph below show the servers behavior before and after the switch:
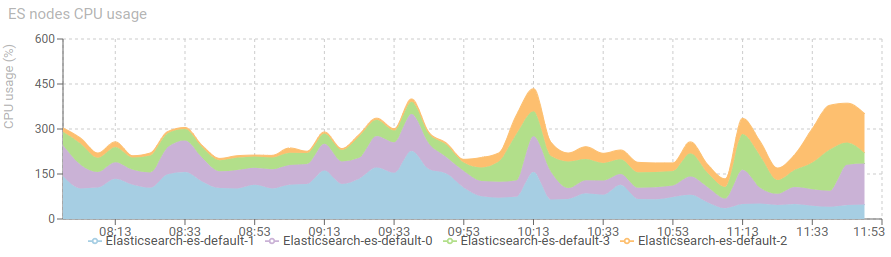
The CPU load got progressively more distributed across the nodes.
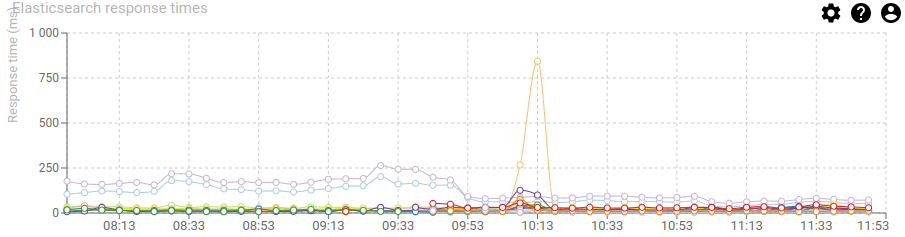
The response time of indexing Http communications (blue and purple) got divided by more than 2!
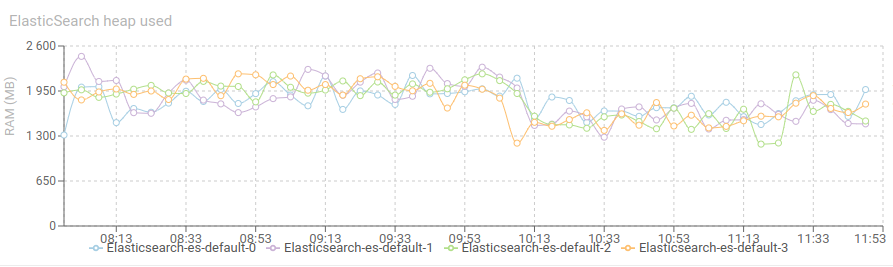
The Heap use of the node got a nice reduction as well 😁
Conclusion
Nice analysis and nice bet.
This option costed me 2-3h to put in place (yes, on 11 services + config and setup).. so low cost, and nice effect :-)
I think Spider scales even better now, and if this routing option dates from Spider beginning, before the aggregation of Whisperers in Whisperers and Instances, it is, now, useless in most cases.
However it could be of use in a SaaS mode, with many and many Whisperers, with a huge ES cluster...
So I kept it :)
Any comment? Contact me !
Cheers!
Thibaut