Health API
· One min read
Spider now features a /health API that exposes the current status of alerting probes.
See Alerting documentation.
The status are integrated in Self Monitoring summary dashboard:

Spider now features a /health API that exposes the current status of alerting probes.
See Alerting documentation.
The status are integrated in Self Monitoring summary dashboard:
Operating and User Interface documentation have been completed. 💪
Part of the roadmap, this was an item highly voted in the User Review last year.
You may now save and reload dashboard configurations.
You may also share them and reuse them with your teams 👍
This november, I launched my second customer satisfaction survey... check the results 😍
Thanks to all of you that participated!
The summary in picture:
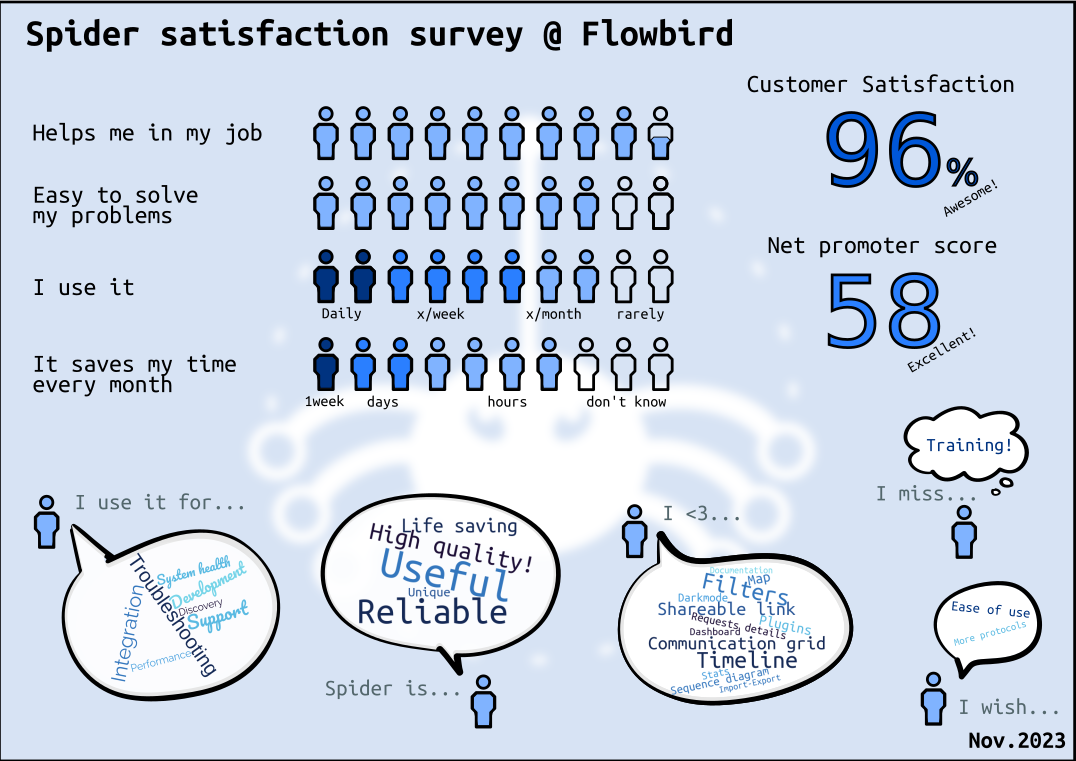
A few days ago I launched my second satisfaction survey.
By contract, Flowbird users are meant to answer these, but how to remind them without spamming them over and over again? 👋
A tester generated the idea: link the form to Spider UI: generate an incentive for users to fill in the survey! Nice idea 💡!
I didn't want it too annoying, but I could easily add a reminder to fill in the survey for any others whose email was not in the Google Form answers.
When finding issues on Flowbird production deployment of Spider, we noticed that there were a small pourcentage of communications that had no answers.
There were not esily noticeable as very small number. But this was abnormal since the application seemed to live good without them.
It could be a bug in Spider!
And it was... or only part of!
Bug seems to be in Redis!
Here is the story of the troubleshooting.
On high volume systems, the map reveals too slow, too crowded to be useful.
I decided to add a predefined dashboard to compensate its usage.
But this dashboard grew beyond my initial thoughts 😅, because it already revealed pretty useful!
Even this first official release includes lots of goodies 🤩!
In production we got a use case when searching for records without responses was important.
That was not easy out of the box and required typing in the free search input in Spider.
To ease our lives, I added the feature to have 'missing' option in some filters drop down.
Patrice L. showed me that when there was too may actors in the sequence diagram, the headers were on top on of another, and it was impossible to identify them.
I thus added a feature to highlight and move to the top the header of the lifeline under the mouse.
Jérémy M mentioned to me recently that this documentation was missing a search feature.
Here it comes!