Reference 'values.yaml'
The following file references all common options in values.yaml helm configuration.
global:
# Spider system version to use
# - use 'latest' to be always up-to-date, frequent upgrades
# - use a date version. Ex: 2020.04.04
version: 2023.09.21
endpoint:
host: spider.mycompany.io # host where ingress will be deployed
publicPath: http://spider.mycompany.io # endpoint on which the UIs and services will be exposed. Ex: http(s)://path.to.server
ip: "" # ip where server runs.
# used when running dev / demo whisperers to inject in host file
# used when running behind a firewall that forces you to use a hostAlias for local-controller to talk with the server
isDemo: false # true to activate demo features (injected whisperers, team and customers, self capture whisperer)
isDev: false # true to activate dev features (change license server)
license:
key: idOfTheLicense
privateKey: 'PEM' # use simple quotes to protect '\n's
jwt: # Key pair to secure communications (jwt)
privateKey: 'PEM'
publicKey: 'PEM'
accessTokenExpiresIn: 'PT15M'
refreshTokenExpiresIn: 'P12W'
extraCaCerts: '-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----\n' # if using self signed S3 or SMTP
smtp:
# email used to send mails
email: spider.analyzer@gmail.com
# smtp server to use
server: smtp.gmail.com
# port of smtp server
port: 465
# is smtp server secured
secure: true
ignoreTLS: false
type: LOGIN # or OAUTH2
loginAuth:
# login and password to use of smtp server is secured
login: spider.analyzer@gmail.com
password: ""
# oAuth options, if smtp server requires oAuth (gmail does)
oAuth:
user:
clientId:
clientSecret:
accessToken:
refreshToken:
expires: 3600
elasticsearch:
password: password # password for elastic user
stillUseV7: false # still deploy with v7 of Elasticsearch to keep compatibility with versions < 2025.09
stores:
# used for customers, whisperers
config:
shards: 1
replicas: 2
# used for links, sessions, jobs
utils:
shards: 1
replicas: 1
#duration before purge - Links
ttl: 6d
rollover: 5d
# used for infra monitoring, beats and raw status
monitoring:
shards: 3
replicas: 0
#duration before purge
ttl: 6d
rollover: 1d
# used for all coms, except UI uploaded data
streamedData:
- name: default
# how many shards to use, should be <= to the number of servers in your Elasticsearch cluster
shards: 3
# how many replicas to use, should be <= to the number of servers-1.
replicas: 0
ttl: 5d
rollover: 12h
- name: shortLife
shards: 3
replicas: 0
ttl: 1d
rollover: 1d
- name: longLife
shards: 1
replicas: 0
ttl: 15d
rollover: 1d
# used for uploaded
uploadedData:
- name: default
shards: 1
replicas: 0
ttl: 5d
redis:
password: password # password for redis user
flips:
postgresqlParsing: true
redisParsing: true
grpcParsing: true
registries:
serverRegistryAuth:
login: test # login to connect to Spider docker registry for servers
password: token # password/token to connect to Spider docker registry
ingress:
useTls: true
tlsSecretName: mySecret # secret for TlS ingress, to be provided outside Spider
className: nginx # name of ingressController to use
annotations: {}
customers:
# array of mails used to send notification mails:
# - account creation notification
supportEmails:
- thibaut.raballand@gmail.com
# if LDAP auth is used
ldapAuth:
active: false
uri: ldap://spider.io:20389
# base path of the users
base: ou=users,dc=streetsmart,dc=global
#other options are available if needed
# if OIDC auth is used
oidcAuth:
active: true
providers:
- name: Google
client_id: ""
client_secret: ""
authorization_endpoint: "https://accounts.google.com/o/oauth2/v2/auth"
token_endpoint: "https://oauth2.googleapis.com/token"
jwks_uri: "https://www.googleapis.com/oauth2/v3/certs"
accounts:
# should account creation form be displayed on login page
creationForm: true
# should reset password form be displayed on login page
# set to no of you only use LDAP auth
resetPasswordForm: true
# should accounts require admin activation
# is not taken into account for LDAP accounts
adminActivation: false
# should send mail to supportEmails on account creation
mailOnCreation: true
teams:
# should send mail to supportEmails on team creation
mailOnCreation: true
admins: # create an admin account at installation (only then)
createAccountsAtInstallation: false
accounts:
- givenName: ""
familyName: ""
email: ""
# when ldapAuth, account is created as admin, and user will authenticate with LDAP
# when Spider auth, account is created with random password,
# and user can reset password with standard feature
ldapAuth: false
controller:
privateKey: 'PEM' # private pem for controller security, same format as jwt key and license key above
publicKey: 'PEM' # public pem for controller security
namespaces: # see controller documentation
blackList:
- spider-system
- kubernetes-dashboard
- cattle.*
gocipher:
privateKey: 'PEM' # private pem for gocipher security, same format as jwt key and license key above
publicKey: 'PEM' # public pem for gocipher security
backup:
active: true # backups configuration data everyday to S3
restoreAtInstallation:
active: false # reloads previous backed up data at installation
date: "2023-01-31" # data of backup restoration
alerting:
tooManyLogs:
# Alerts when last minutes are showing too many errors
active: true
maxErrorLogsPerMin: 10
stuckGocipher:
# Alerts when a gocipher instance is persistently failing to send TLS secrets
active: true
minErrorsPerMin: 0.2
noNewStatus:
# Alerts when Whisperers are not sending anything
active: true
minStatusPerMin: 5
infraChange:
# Alerts when servers are added / removed
active: true
lowESFreeSpace:
# Alerts when ES is getting low free space
active: true
minESFreeSpaceInGB: 10
healthcheckES:
# Alerts when ES health is yellow or red
active: true
healthcheckRedis:
# Alerts when the free memory in Redis gets too low
active: true
minRedisFreeMemoryInMB: 100
parsingDelay:
# Alerts when the delay for parsing gets too long
active: true
threshold: PT30S
licenseInvalid:
# Alerts when license is getting invalid in the month
active: true
oldLicenseStats:
# Alerts when license stats are too old
active: true
threshold: PT13H
pollingQueued:
# Alerts when too many items are in the queues
active: true
threshold: 20000
gui:
networkview:
#Tell if usage statistics for Users sessions sent to server default to anonymous or with user's id+email
namedStatistics: false
pluginsStore:
#Tell if plugins store should be global (in the cloud) or local to this instance
global: true
api:
authenticatedHealthApi: false
tuning:
shutdownDelay: 3 # duration in s before shutting down services (allow scaledown without issue)
# Tell if ES indices are sharded / routed by the whisperers id.
# Activate if you have many different whisperers over many shards to route indexing and searching on current indices
# Deactivate if you have few whisperers and you want to scale indexing over all shards
useWhispererRoutingWithES: false
# Tell if Spider should compress Payloads before saving in Redis
# See documentation for details and effects
compressRedisPayloads:
httpComs: true
httpComContents: true
httpPers: true
# Tell if most used APIs calls should be compressed
# See documentation/blog for details and effects
compressApis:
packRead:
getPacketsOfTcpSession: false
tcpUpdate:
postParsingJob: true
webWrite:
tcpSessions: true
############# Spider infrastructure
# Elastic, Kibana, Filebeat, Metricbeat
elasticsearch:
nodes: 1 # count of requested nodes in the cluster
resources:
requests:
cpu: 1 # cpu requests and limit
memory: 1Gi # memory size request (Gi)
limits:
cpu: 1 # cpu requests and limit
memory: 1Gi # memory size request (Gi)
volume:
size: 1Gi # size (Gi) of volume to create for each node
storageClassName: # storageClass to use
# ECK operator installation (optional).
# Set eck.enabled: true only when no ECK operator is running in the cluster,
# or when an existing ECK is namespace-scoped and does not watch Spider's namespace.
# Leave false (default) if a cluster-wide ECK already manages all namespaces.
eck:
enabled: false
eck-operator:
managedNamespaces: # namespaces the operator watches; change if Spider is not in spider-system
- spider-system
createClusterScopedResources: true # false if another namespace-scoped ECK already created ClusterRoles
# Avaiable redis in memory stores
redis:
redisPack:
maxmemory: 1Gb
redisTcp:
maxmemory: 1Gb
redisShared:
maxmemory: 1Gb
# S3 backup
s3Backup:
accessKeyId:
secretAccessKey:
region:
endpoint:
bucket:
# Traefik gateway
gateway:
replicas:
min: 1
max: 20
cpuThreshold: 500m
# Spider microservices
# Extra Kubernetes options are available for taints, debug and demo
# Below are classical options that you might want to change
services:
captureStatusPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
ciphers:
autoscaling:
min: 1
max: 20
cpuThreshold: 500m
ciphersStatus:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
ciphersStatusAgg:
autoscaling:
enabled: false
ciphersStatusPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
ciphersRawStatusPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
config:
autoscaling:
min: 1
max: 20
cpuThreshold: 500m
customer:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
guiLogs:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
guiSettings:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
hosts:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
hostsPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
jobs:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
links:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
mailSender:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
monitorRead:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
packPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
packRead:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
packUpdate:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
packWrite:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
parsingStatusHttpPersPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
parsingStatusTcpSessionPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
plugins:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
sessions:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
tcpPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
tcpRead:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
tcpUpdate:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
tcpWrite:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
teams:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
tlsKeys:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
tlsKeysLinker:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
webHttpComContentPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
webHttpComPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
webHttpPersPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
webRead:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
webUpload:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
webWrite:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
whispStatusPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
threadsCount: 1
whisp:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
whispsStatus:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
More values are available to tweak configuration or to develop Spider. However, most useful values for production are listed in this page.
Version
global:
# Spider system version to use
# - use 'latest' to be always up-to-date, frequent upgrades
# - use a date version. Ex: 2020.04.04
version: 2023.04.11
The version specifies what version of Spider to deploy.
Spider uses systems version, which means that all components are tagged with the same version, ensuring consistency of the release.
Obtaining the versions list
Latest stable version is listed on Spider homepage.
Available systems versions are listed in CHANGELOG
For now, only the version latest and the last dated stable are guaranteed to be available.
Previous versions may be removed from the store without warning.
Endpoint
global:
endpoint:
host: spider.mycompany.io # host where ingress will be deployed
publicPath: http://spider.mycompany.io # endpoint on which the UIs and services will be exposed. Ex: http(s)://path.to.server
ip: "" # ip where server runs.
# used when running dev / demo whisperers to inject in host file
# used when running behind a firewall that forces you to use a hostAlias for local-controller to talk with the server
publicPathandhostare often related values, but they may be different.- When
ipis set, a HostAlias is created for the local-controller to talk to the server- Set it when you need local-controllers (and thus whisperers) to talk to Spider without exiting local network - for security, or cost
License
global:
license:
key: idOfTheLicense
privateKey: 'PEM' # use simple quotes to protect '\n's
License is obtained by purchasing Spider at Floocus.
The key identifies your license, and the privateKey is used to secure the authentication with Floocus central system.
Without a license, Spider does not capture nor parse communications.
As for the JWT keys, the PEM is expected to be given as a one-liner with \n.
Example:
global:
jwt:
publicKey: '-----BEGIN RSA PUBLIC KEY-----\nMIGJAoGBAL8sa4fGv/dWCwe8Ssff+bIxWWEPVIfGByhPd0MbEMVyZk0p2Ex4Wokn\naDxqax2+am+SYRoQcgBR8MUMlopGYzoioWvqR8kaBR4SPU2v34MRlGxLE/YMs4tJ\ntg7r/wdVa2IXjUoZcFoC0IqdSmwQuYKWQlNOEvcCxe0MfERS2JzfAgMBAAE=\n-----END RSA PUBLIC KEY-----'
JWT
global:
jwt: # Key pair to secure communications (jwt)
privateKey: 'PEM'
publicKey: 'PEM'
accessTokenExpiresIn: 'PT15M'
refreshTokenExpiresIn: 'P12W'
This keypair is used to sign JWT tokens issues by services for their related identity tokens:
configfor appscustomersfor usersteamsfor team tokenswhispsfor Whisperer agentscontrolsfor Controller agentsciphersfor Gocipher agents
You may define custom TTL for both accessToken with accessTokenExpiresIn and refreshToken with refreshTokenExpiresIn.
- Access tokens are issued to all clients (users, apps and agents)
- Refresh tokens are issued only to users.
- They allow keeping the session open.
- Refresh tokens are stored in strict, secured, HTTP only, restricted path cookies
Generating a key pair with OpenSSL
To generate the key pair, you may use OpenSSL:
$ openssl genrsa -out privateKey.pem 2048
Generating RSA private key, 2048 bit long modulus
..........+++
..........................................................................+++
e is 65537 (0x10001)
$ openssl rsa -in privateKey.pem -outform PEM -pubout -out publicKey.pem
writing RSA key
You need then to transform the PEM files to provide them as values:
$ cat publicKey.pem | sed ':a;N;$!ba;s/\n/\\n/g'
$ cat privateKey.pem | sed ':a;N;$!ba;s/\n/\\n/g'
This gives out a string to copy in the values.yaml file:
privateKey: '-----BEGIN RSA PUBLIC KEY-----\nMIGJAoGBAI ... L9dOrMfpFAgMBAAE=\n-----END RSA PUBLIC KEY-----'
Supported formats
Spider services and agents support RSA keys in both PKCS#1 and PKCS#8 for keys format.
| Format | PEM |
|---|---|
| PKCS#1 | -----BEGIN RSA PUBLIC KEY----- ... -----END RSA PUBLIC KEY----- |
| PKCS#8 | -----BEGIN PUBLIC KEY----- ... -----END PUBLIC KEY----- |
Default format generated by Openssl command changed to PKCS#8 with version 3.0.
If you wish to get PKCS#1 with latest Openssl version, you must adapt the above commands with -traditional:
openssl genrsa -traditional -out privateKey.pem 2048
Updating the JWT keys
You may update the security keys at any time in the values file. All service will restart automatically when applied by Helm.
Demo mode
global:
isDemo: false # true to activate demo features (injected whisperers, team and customers, self capture whisperer)
When set to true:
- A
Demo teamis created - 2 users are created
Owner user, that owns whisperersBasic user, that are only shared access
- 3 whisperers are created
Self capture, belonging toDemo teamOwn whisp, belonging toOwner userUpload, belonging toOwner user
Self capture whisperers is capturing a few services from Spider itself:
- Web-read
- Hosts
- Whisp
These resources allow you to test with Spider configuration and capture without any system to capture.
Dev mode
global:
isDev: false # true to activate dev features (change license server)
When set, Spider connects to a Floocus development license server, and some debug features are made available.
Extra CA
global:
extraCaCerts: '-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----\n' # if self signed S3 or SMTP
If you have secured your S3 or SMTP server with a custom Certificate Authority, you may provide its certificate in extraCaCerts so that Spider will accept connecting to them.
SMTP
global:
smtp:
# email used to send mails
email: spider.analyzer@gmail.com
# smtp server to use
server: smtp.gmail.com
# port of smtp server
port: 465
# is smtp server secured
secure: true
ignoreTLS: false
type: LOGIN # or OAUTH2
loginAuth:
# login and password to use of smtp server is secured
login: spider.analyzer@gmail.com
password: ""
# oAuth options, if smtp server requires oAuth (gmail does)
oAuth:
user:
clientId:
clientSecret:
accessToken:
refreshToken:
expires: 3600
Spider uses SMTP to send mail notifications for:
- Accounts changes
- Teams changes
- Alerting
- ...
The main configuration options are self explanatory:
email- address used as 'sender' when sending emailserver&port- smtp serversecure- use secure SMTP protocol (with TLS) or not, with credentialsignoreTLS- accept self-signed certificate
Then, the type tells if the authentication when secured is done using LOGIN auth or OAUTH2.
- In
LOGIN, specify theloginAuth.loginandloginAuth.passwordparams. - In
OAUTH2, specify theoAuth.*parameters.
Elasticsearch indices setup
global:
elasticsearch:
password: password # password for elastic user
stillUseV7: false # still deploy with v7 of Elasticsearch to keep compatibility with versions < 2025.09
stores:
# used for customers, whisperers
config:
shards: 1
replicas: 2
# used for links, sessions, jobs
utils:
shards: 1
replicas: 1
#duration before purge - Links
ttl: 6d
rollover: 5d
# used for infra monitoring, beats and raw status
monitoring:
shards: 3
replicas: 1
#duration before purge
ttl: 6d
rollover: 1d
# used for all coms, except UI uploaded data
streamedData:
- name: default
# how many shards to use, should be <= to the number of servers in your Elasticsearch cluster
shards: 3
# how many replicas to use, should be <= to the number of servers-1.
replicas: 0
ttl: 5d
rollover: 12h
- name: shortLife
shards: 3
replicas: 0
ttl: 1d
rollover: 1d
- name: longLife
shards: 1
replicas: 0
ttl: 15d
rollover: 1d
# used for uploaded
uploadedData:
- name: default
shards: 1
replicas: 0
ttl: 5d
This part configures the indices used by Spider to store data.
Password
The password that will be used for the elastic user used by Spider to connect to Elasticsearch.
- You might also connect to Kibana with it
- Use a strong one!
We recommend you to create other users in Kibana on your own, should you want to perform direct queries on the captured data.
Shards & replicas
Indices, in Elasticsearch, may have:
shards- to spread data across nodes.- Should be lower than the number of nodes in the cluster
- Should be > 1 only for big data indices
replicas- to have high availability, and read copy of the data for more throughput in search
Having replicas of streamed data will lead to A LOT OF volume requirements!
All data is copied to all replicas.
Index lifecycle management
Spider indices are already optimised with their own Index Lifecycle Management rules (ILM).
ILM define how the time based indices move from a write optimisation to a read optimisation during their life, and when they finally are deleted.
They allow continuous storage of Spider data with a limit on how long data is stored, allowing to control the volume required.
ILM have a few parameters to tune them:
ttl- duration of data availabilityrollover- duration of the 'write' index (and of each index in the system), before it becomes read only- When the load is big, you should reduce this duration, to have smaller indices.
Index categories
The indices are split in 4 categories:
config- Indices that store the configuration data (customers, teams, whisperers...)
- They don't have ILM as the data is kept forever (except deleted data).
utils- Indices used to store data for UI (links, jobs...)
monitoring- Indices used to store all monitoring data
streamedData- Indices that store the captured communication data (HTTP communication, TCP sessions, Packets, Hosts, Parsing status...)
- They have an ILM defined
uploadedData- Indices that store the communication data uploaded from the UI (HTTP communication, TCP sessions, Packets, Hosts, Parsing status...)
- Upload indices have a specific ILM with - usually - a longer TTL
Data Storage Policies
streamedData and uploadedData sections are arrays.
Indeed, you may define here several storage policies, each with a distinct name and a different TTL.
This allows having part of your captured data stored with different retention time depending on the Whisperer that captures them.
Rules:
- You have to setup DSP for both
streamedDataanduploadedData. - You have to define a
defaultDSP, or Spider pollers will not start. - The
nameyou give is used- to name Elasticsearch ILM, templates and indices
- to display in the Whisperer configuration tabs
- The
namemay contain uppercase letters, but not spaces. They must be unique.
::: warning No control is made on the uniqueness or on the absence of spaces. Result will be bad 😅 :::
Limits:
- When removing a policy,
- the existing data indices are not removed straight, they will be removed at the end of their existing TTL
- the existing Elasticsearch objects (templates, ILM...) are not removed automatically
- When updating a policy
- the existing data will stay associated with the policy at time of their indexing
- only the new data will be associated to the new policy
Take care not to have too many different policies:
- Each policy will create a set of indices to store data and the number of indices an Elasticsearch cluster may manage is limited
- When searching data, the search will be done on indices linked to ALL data policies. The more, the slower.
Redis security setup
global:
redis:
password: password # password for redis user
The password that will be used for the spider user used by Spider to connect to Redis.
- Use a strong one!
Default user without password is disabled on Redis by the setup
Feature flags
flips:
postgresqlParsing: true
redisParsing: true
grpcParsing: true
postgresqlParsingactivates PostgreSQL parsing.redisParsingactivates Redis parsing.grpcParsingactivates gRPC (gRPC-over-HTTP/2) parsing.
Each flag deploys (or not) the dedicated parser, read service, pollers, Redis cache instance and Elasticsearch indices for that protocol. Leave a flag off (the default) to avoid the extra microservices and indices when you do not capture that protocol.
Registries
registries:
serverRegistryAuth:
login: test # login to connect to Spider docker registry for servers
password: token # password/token to connect to Spider docker registry
Sets the credentials to connect to Spider Docker registry.
serverRegistryAuthis mandatory as it is required to download Spider services images.
The tokens are issued with Spider license.
Ingress
ingress:
useTls: true
tlsSecretName: mySecret # secret for TlS ingress, to be provided outside Spider
className: nginx # name of ingressController to use
annotations: {}
Spider needs to expose its own gateway for Whisperers to upload data, and the UIs to be accessible.
The ingress may or not be HTTPS, using Tls to secure communications.
In this case, the tlsSecretName is required to associate the SSL certificate to the ingress.
The secret being often created (and even reflected) from certmanager or another tool, only the name is expected here.
Spider is not coupled to any ingress className.
Even if Spider uses Traefik internally as API gateway, the later may be exposed using any other ingress, as in the example above, using nginx.
Customers
The customers block allows configuring:
- Login form options
- Connection means
- Creation of administrators
Options
customers:
# array of mails used to send notification mails:
# - account creation notification
supportEmails:
- thibaut.raballand@gmail.com
accounts:
# should account creation form be displayed on login page
creationForm: true
# should reset password form be displayed on login page
# set to no of you only use LDAP auth
resetPasswordForm: true
# should accounts require admin activation
# is not taken into account for LDAP accounts
adminActivation: false
# should send mail to supportEmails on account creation
mailOnCreation: true
teams:
# should send mail to supportEmails on team creation
mailOnCreation: true
Accounts creation
accounts.creationFormwill display a linked to allow a user to create its own Spider account on the login page.
When not active, then account creation may only be done through:
- Manual account creation by an administrator on the UI.
- Automatic account creation by LDAP authentication.
You may receive a mail in all account creations with accounts.mailOnCreation option.
Then all supportEmails will be notified.
Once the account is created, you may wish to validate the account manually.
- This is done by setting
accounts.adminActivationoption - The mails listed in
supportEmailswill be notified that an account has to be activated - Activation is done by editing the user profile on the UI and switching its state from
DRAFTtoACTIVE.
Teams creation
You may also be notified on teams creation using teams.mailOnCreation option.
Forgot your password
accounts.resetPasswordForm activates a link on the login page to reset a users password in case of a forgotten password.
Process:
- The user enters his/her email address
- A mail is sent to the user with link to reset its password
- The link includes a limited in time token
- The link routes the user to a form to set its password (with confirmation)
- The new password is sent to the server with the token id. The token is checked before accepting the new password.
This feature is not possible for LDAP authenticated users.
Authentication means
LDAP
customers:
# if LDAP auth is used
ldapAuth:
active: false
uri: ldap://spider.io:20389
# base path of the users
base: ou=users,dc=streetsmart,dc=global
Users may authenticate natively to Spider, but they also may connect with a LDAP account.
The options above allows LDAP configuration.
The base option sets where the user account are located in the LDAP.
Process:
- At login, Spider searches the user in the LDAP using the email provided in input.
- If a user is found in the LDAP, Spider tries to bind the user with its password.
- If successful, Spider checks if the user exists in its own database to:
- Either connect it,
- Or create a new account, in case of a new user.
OpenId Connect
customers:
oidcAuth:
active: true
providers:
- name: Google
client_id: ""
client_secret: ""
authorization_endpoint: "https://accounts.google.com/o/oauth2/v2/auth"
token_endpoint: "https://oauth2.googleapis.com/token"
jwks_uri: "https://www.googleapis.com/oauth2/v3/certs"
- name: Gitlab
client_id: ""
client_secret: ""
authorization_endpoint: "https://gitlab.com/oauth/authorize"
token_endpoint: "https://gitlab.com/oauth/token"
jwks_uri: "https://gitlab.com/oauth/discovery/keys"
- name: GitHub
client_id: ""
client_secret: ""
authorization_endpoint: "https://github.com/login/oauth/authorize"
token_endpoint: "https://github.com/login/oauth/access_token"
userinfo_endpoint: "https://api.github.com/user"
jwks_uri: "https://token.actions.githubusercontent.com/.well-known/jwks"
scope: "openid email profile user"
Users may also authenticate to an external Identity Provider (IP) using OpenId Connect protocol.
Configuration
The options above demonstrate several OIDC configurations at once.
- You may define as many IPs as you need
- The options naming is matching standard labels for OIDC parameters
client_idandclient_secretare specific to Spider (see below), and generated by the IP- The URLs are often listed in a well-known endpoint such as
- The scope is the list of OAuth2 scope requested by Spider when connected
- They must allow fetching the
email,family_name,given_nameof a connected user - Usually:
openidallows getting anid_tokenfrom the originalcodereceived, while calling thetoken_endpointemailis required for Spider to authenticate the userprofileoruserare often required to get the user info to create the account- If not provided, Spider will create the account with
CHANGE MEvalue
- If not provided, Spider will create the account with
- They must allow fetching the
scopeanduserinfo_endpointare optional
To get the values to fill in, usually, you have to:
- Register an application in your identity provider application / client list
- Give it a name, such as
Spider Analyzer - Provide the application URL that the IP will redirect to.
- For Spider:
https://{global.endpoint.publicPath}/login/andhttps://{global.endpoint.publicPath}/loginif you are using https - Replace
global.endpoint.publicPathby the value you've set earlier 😉
- For Spider:
- Get in return the
client_idandclient_secretto provide here - Find the .well-kown/openid-configuration of your IP
Authentication process
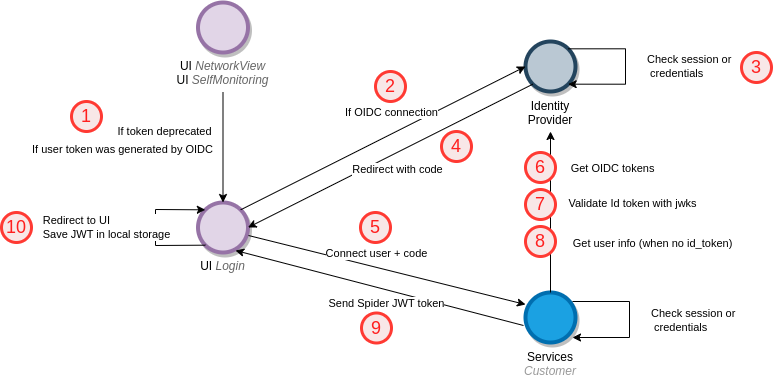
Spider implements the authorization code grant:
- Network View and Monitoring UI redirects to Login UI
- With user email and identity provider (IP) if the user was previously connected with OIDC
- Login UI redirects to the IP to get a
code, usingauthorization_endpoint,client_idandscope
- Automatically with an email hint when
emailhas provided by the UIs - When user click on the IP name in the login page
- The IP validate the user session or display a login page, then validates the credentials.
- The IP redirects to Login UI with a
code - Login UI calls Customers service with the
codeand provider name to get the user token - Customers service takes the
codeand exchange it to anaccess_tokenand andid_tokenusing theclient_idandclient_secret - Customers service validates the
id_tokenwith the public keys provided onjwks_uri - Customers service gets the email from the
id_tokenor theuserinfo_endpointusing theaccess_tokenwhen the former is not provided - Customers sends a signed Spider token when everything goes well
- The token is saved in local storage by the UI then used between Spider components as usual. Login redirects back to orginal UI.
This flow allows to keep the secret in the backend, not revealing it on the client side.
When a user is using a token generated with an OIDC flow, on page load or refresh, it redirects to the login UI with predefined parameters to check if the IP connection is still valid.
It does it with a grace period of 1 minute after login. Not to do infinite redirects 😅
Spider does not support Single Log Out, nor Front or Back-channel logouts.
Logging out from Spider will only log the user out from Spider.
By choice.
Admin creation
customers:
admins: # create an admin account at installation (only then)
createAccountsAtInstallation: false
accounts:
- givenName: ""
familyName: ""
email: ""
# when ldapAuth, account is created as admin, and user will authenticate with LDAP
# when Spider auth, account is created with random password,
# and user can reset password with standard feature
ldapAuth: false
When installing Spider, no 'standard' or 'generic' administration account exists. That ensures better security.
You may set a list of accounts to 'pre-create' at installation.
These account will be created as administrators, with a random, unknown password.
Then,
- Either the administrator set its own password using the Reset password form.
- Either it is connecting with LDAP (when set)
This process allows to never share or communicate an administrator password.
Controller
controller:
privateKey: 'PEM'
publicKey: 'PEM'
When installing Spider, it automatically setups a Controller on the cluster it is installed.
The Controller is used to attach Whisperers to any Workload of the cluster through the UI.
The Controller needs two keys to allow it to access the server:
- The
privateKeyfor its secret configuration - The
publicKeyis saved in the Controller resource in the server
See Generating a key pair with OpenSSL.
Limit namespaces
controller:
namespaces:
blackList:
- spider-system
- kubernetes-dashboard
- cattle.*
whiteList:
- myNamespace
You may limit on which namespaces the Whisperers may be spawned using blackList and whiteList.
They both accept regular expressions:
blacklistprevents using these namespaceswhiteListlimits access to only these namespaces
Resource generation
controller:
createLocalController: true
The local controller resource record is generated by Helm and injected in Elasticsearch.
the 'time based' data of the resource (creation date...) are injected by the initES init container, thus making the rendered manifests stable and compatible with ArgoCD tool.
Updating the security keys
You may update the keys once the resource is created. This will ONLY update the stored key in the stored resource. Others changes - name, permissions... - are not overridden when you're updating the keys through Helm.
However, due to the values file structure, the Controls and local-controller components will not restart automatically on this change, you have to restart them manually to apply the key change.
Using the CLI and kubectl, you may restart these components like this:
kubectl -n spider-system rollout restart deployment controls
# wait for controls services to restart
kubectl -n spider-system rollout restart deployment local-controller
Gocipher
gocipher:
privateKey: 'PEM'
publicKey: 'PEM'
When installing Spider, it automatically setups a Gocipher daemonset on the cluster it is installed.
The Gocipher is used to capture TLS keys on any Workload a Whisperer is attached to.
The Gocipher needs two keys to allow it to access the server:
- The
privateKeyfor its secret configuration - The
publicKeyis saved in the Cipher resource in the server
See Generating a key pair with OpenSSL.
Resource generation
gocipher:
createLocalGocipher: true
The local gocipher resource record is generated by Helm and injected in Elasticsearch.
the 'time based' data of the resource (creation date...) are injected by the initES init container, thus making the rendered manifests stable and compatible with ArgoCD tool.
Updating the security keys
You may update the keys once the resource is created. This will ONLY update the stored key in the stored resource. Others changes - name, permissions... - are not overridden when you're updating the keys through Helm.
However, due to the values file structure, the Ciphers and local-gocipher components will not restart automatically on this change, you have to restart them manually to apply the key change.
Using the CLI and kubectl, you may restart these components like this:
kubectl -n spider-system rollout restart deployment ciphers
# wait for ciphers services to restart
kubectl -n spider-system rollout restart daemonset local-gocipher
Backup
backup:
active: true # backups configuration data everyday to S3
backup.active activates regular backup of configuration resources.
- Backup is done every day to the S3 store configured at
s3Backupkey in the infrastructure part of the values file. - The configuration resources saved are:
- Customers
- Teams
- Whisperers
- UiSettings
- They are saved as plain bulk creation request for Elasticsearch
- A new file is saved every day
No automatic removal of old files is done.
We advise you to set some bucket lifecycle policy to automatically remove oldest files.
Restore at installation
backup:
restoreAtInstallation:
active: false # reloads previous backed up data at installation
date: "2023-01-31" # data of backup restoration
You may wish to restore a previous backup when installing Spider.
The backup files from the reuested date are loaded from the S3 configured in s3Backup key.
This is done by a post install Kubernetes Job that runs only at Helm installation, and that waits for Elasticsearch (and indices) availability.
Date must be between quotes
Do not combine automatic administrator accounts creation and backup restoration if administrator accounts exist in the backup.
Then two accounts would exist with the same email, which is not managed by Spider.
Alerting
alerting:
tooManyLogs:
# Alerts when last minutes are showing too many errors
active: true
maxErrorLogsPerMin: 10
stuckGocipher:
# Alerts when a gocipher instance is persistently failing to send TLS secrets
active: true
minErrorsPerMin: 0.2
noNewStatus:
# Alerts when Whisperers are not sending anything
active: true
minStatusPerMin: 5
infraChange:
# Alerts when servers are added / removed
active: true
lowESFreeSpace:
# Alerts when ES is getting low free space
active: true
minESFreeSpaceInGB: 10
healthcheckES:
# Alerts when ES health is yellow or red
active: true
healthcheckRedis:
# Alerts when the free memory in Redis gets too low
active: true
minRedisFreeMemoryInMB: 100
parsingDelay:
# Alerts when the delay for parsing gets too long
active: true
threshold: PT30S
licenseInvalid:
# Alerts when license is getting invalid in the month
active: true
oldLicenseStats:
# Alerts when license stats are too old
active: true
threshold: PT13H
pollingQueued:
# Alerts when too many items are in the queues
active: true
threshold: 20000
Alerting let you configure the alerts to activate and their thresholds.
See Alerting for a complete documentation.
GUI options
gui:
networkview:
#Tell if usage statistics for Users sessions sent to server default to anonymous or with user's id+email
namedStatistics: false
pluginsStore:
#Tell if plugins store should be global (in the cloud) or local to this instance
global: true
gui.networkview.namedstatistics tells if statistics captured on the ui (actions clicked, options active, whisperers selected) are associated with the user id, or an anonymous random id.
This set the 'default setting'. The user may always change its own setting.
gui.networkview.pluginsStore.global tells if the plugins store to search and store plugins is global, Floocus one, or a local one (from current setup).
See Plugins Store from more information.
API options
api:
authenticatedHealthApi: false
authenticatedHealthApi tells if the /health API should be exposed with authentication or not.
If set to true, then a Spider token will be expected, but no authorization check will be perfomed.
Tuning
tuning:
shutdownDelay: 3 # duration in s before shutting down services (allow scaledown without issue)
# Tell if ES indices are sharded / routed by the whisperers id.
# Activate if you have many different whisperers over many shards to route indexing and searching on current indices
# Deactivate if you have few whisperers and you want to scale indexing over all shards
useWhispererRoutingWithES: false
Shutdown Delay
shutdownDelay defines how long to wait for services before shutting down.
You may need to increase it to avoid errors when autoscaling scales down the nodes.
This depends on your Kubernetes distribution:
- On AWS EKS, 1s seems enough.
- On Nutanix Karbon, setting it to 10s was required.
See this blog post for more details.
Sharding routing
useWhispererRoutingWithES tells if Spider should use Whisperers' id to route the data across ES shards.
Should be used only for high cardinality setups.
See this blog item on the topic.
Compress Redis payloads
tuning:
compressRedisPayloads:
httpComs: true
httpComContents: true
httpPers: true
Allow activating or not Snappy compression of payloads stored in Redis.
See study in this blog post.
Compress APIs
tuning:
packRead:
getPacketsOfTcpSession: false
tcpUpdate:
postParsingJob: true
webWrite:
tcpSessions: true
Activate or not compression of main used internal API calls.
See study in this blog post.
Infrastructure setup
This part explains infrastructure options of Spider setup.
Elasticsearch
# Elastic, Kibana, Filebeat, Metricbeat
elasticsearch:
nodes: 1 # count of requested nodes in the cluster
resources:
requests:
cpu: 1 # cpu requests and limit
memory: 1Gi # memory size request (Gi)
limits:
cpu: 1 # cpu requests and limit
memory: 1Gi # memory size request (Gi)
volume:
size: 1Gi # size (Gi) of volume to create for each node
storageClassName: # storageClass to use
# ECK operator — optional, see section below
eck:
enabled: false
eck-operator:
managedNamespaces:
- spider-system
createClusterScopedResources: true
Those settings allow to set:
- The number of
nodesin the Elasticsearch cluster.- They will all be master, data and ingest with current settings.
- The more nodes, the more ingestion capabilities you will have.
- Kubernetes
resourcesfor each node. - The persistent
volumeclaim for each node. With itssizeandstorageClassName.- Depending on the following settings for retention time of indices, you might need hundreds of Gigabytes.
ECK operator
Spider manages its Elasticsearch cluster through the Elastic Cloud on Kubernetes (ECK) operator.
By default (eck.enabled: false) Spider assumes an ECK operator is already running in the cluster and will use it.
Set eck.enabled: true when no ECK is present, or when an existing ECK is namespace-scoped and does not watch Spider's namespace. See the installation guide for the required two-step process.
| Scenario | eck.enabled | createClusterScopedResources |
|---|---|---|
| No ECK in cluster | true | true |
| Namespace-scoped ECK, doesn't watch Spider's namespace | true | false |
| Cluster-wide ECK watches all namespaces | false | — |
managedNamespaces lists the namespaces the ECK operator will watch. Change it if Spider is deployed outside of spider-system.
Spider's preflight check will abort the install if a cluster-wide ECK operator is detected in elastic-system. Read the error message — it tells you which option to set.
Redis
redis:
redisPack:
maxmemory: 1Gb
redisTcp:
maxmemory: 1Gb
redisShared:
maxmemory: 1Gb
As current configuration, Spider uses 3 Redis nodes, without High Availability.
- redisPack - stores unitary Packets data
- redisTcp - stores Tcp sessions and parsing status
- redisShared - stores all other data
You may change the maximum memory used by Redis.
When Redis reaches this amount, it starts dropping data.
S3
# S3 backup
s3Backup:
accessKeyId:
secretAccessKey:
region:
endpoint: # include prefix "https://" if you are connecting to secure endpoint
bucket:
These settings define connection settings to the S3 - compatible - store to backup and restore configuration data.
regionmay not be required if you have a local S3 compatible setupendpointrequireshttps://prefix to connect to a secured endpoint. Otherwise, you might end up withERR_INVALID_URLerrors.
Gateway
# Traefik gateway
gateway:
replicas:
min: 1
max: 20
cpuThreshold: 500m
Spider uses Traefik to expose:
- APIs for the Whisperers
- APIs for the UI
- Kibana
You may define its autoscaling settings.
You may also customise the services to expose by customising servicesToExpose key (advanced configuration).
gateway:
servicesToExpose:
- name: ciphers
- name: ciphers-status
- name: customer
- name: gui-logs
- name: gui-settings
- name: hosts
- name: link
- name: login
- name: job
- name: monitor-read
- name: networkview
prefix: network
- name: pack-read
- name: pack-write
- name: plugins
- name: self-monitoring
- name: session
- name: tcp-read
- name: tcp-write
- name: teams
- name: tls-keys
- name: web-parser
- name: web-read
- name: whisp
- name: whisps-status
- name: kibana-kb-http
prefix: kibana
port: 5601
Services
# Spider microservices
# Extra Kubernetes options are available for taints, debug and demo
# Below are classical options that you might want to change
services:
captureStatusPoller:
autoscaling:
min: 1
max: 20
cpuThreshold: 300m
resources:
requests:
cpu: 2m
memory: 110M
threadsCount: 1
extraConfiguration: {}
...: ...
autoscaling let you customise the scaling capabilities of Spider microservices.
- The microservices will autoscale to have a maximum of
cpuThresholdcpu usage for each replica of the service. - You may set the minimum and maximum count of replicas.
resources let you change the requests Kubernetes resources for each service.
threadsCount let you define you many 'threads' are polling in parallel in the same poller.
This setting allows you to scale polling without adding more PODs and using much more RAM.
If the threadsCount is too high, the CPU usage of the poller may raise above the cpuThreshold... and it will scale.
extraConfiguration let you override any default configuration of any service.
Services list
The complete services list is available in Services configuration.
In the helmchart:
- The default
values.yamlof the main Chart lists the services and settings that you may change. - The
values.yamlin the sub-chartspider-microserviceslist all services, but you should avoid playing with the settings.
Dev & demo
Other options are available for development and demo, but they are out of this page scope.